Run, don’t walk, to replace your iPhone battery for $29
Apple Genius Bar employees assist customers at the company’s Fifth Avenue store in New York. (John Moore/Getty Images)
Rarely is tech advice this cut and dried: If you bought an iPhone in 2016 or earlier, make an appointment at a Genius Bar as soon as possible. Apple just started a program that can make old iPhones feel new again — for just $29.
An Apple store or repair shop will pop the hood of your iPhone 6, 6s, SE or 7 and swap out the battery. Like a jalopy after a Jiffy Lube, a three-year-old iPhone with a fresh battery will not only run longer, chances are it will also run faster.
Just hurry up and do it. When I showed up with an appointment at my closest Apple store on Jan. 3, there were so many others also trying to replace their batteries that I had to join a weeks-long waiting list. Your local shop might have more supply, but battling hordes for repair (rather than a sexy new phone) is an unusual experience at an Apple store.
A Chicago Apple store employee demonstrates an iPhone 6s. (Photo by John Gress/Getty Images)
But now there’s a fix. While most of us were in a holidaze last week, Apple published a mea culpa and promised to make replacing the battery on an iPhone less expensive through the end of 2018. It made the move, it said, “to address our customers’ concerns, to recognize their loyalty and to regain the trust of anyone who may have doubted Apple’s intentions.” On Dec. 30, Apple said it would begin honoring a $29 price immediately.
This is going to cost Apple a lot more than just overtime at the Genius Bar. Once your phone get a fresh battery and the processor kicks back to 100 percent, there’s a chance you might not feel the need to upgrade your iPhone for a while. One analyst, Mark Moskowitz of Barclays, expects the battery offer could cause Apple to sell 16 million fewer new iPhones. (And you definitely shouldn’t buy a phone you don’t need; here’s my advice on whether you should upgrade to this year’s iPhone 8 and X.)
Still, inexpensive battery replacement is the right thing for Apple to do. A good reputation is its best selling point in an era where smartphone features are reaching parity. Battery life is most people’s No. 1 complaint about their phones, and maintenance is a long-overdue part to smartphone ownership. When Apple makes repairing phones as easy as buying new ones, it saves us money and it’s better for the environment.
How to replace an iPhone battery
An iPhone 6 battery from a teardown by gadget repair site iFixit. (Photo: iFixit)
How do you know if you’d benefit from a new battery? Apple has promised a software update soon that gives us more visibility into battery health. For now, though, if your phone is really bad off there might be a warning message when you dig into the settings menu. Or here’s a yardstick: If your iPhone can’t last from morning coffee to happy hour on a single charge, it’s time.
Anyone with an iPhone 6 or newer is eligible for the $29 replacement, regardless of what Apple’s battery tests report. (If you paid for AppleCare+ coverage, it might even be free.) Remember, this isn’t just about improving battery life; some tests have found replacing the battery can result in speed improvements of over 100 percent.
To get a new battery, log on to Apple’s support site, and then select iPhone, then Battery, then Battery replacement. If you live near an Apple store or authorized repair shop such as Best Buy, select one and make an appointment. (Call ahead to third-party shops to make sure they’ll honor the $29 offer.)
Then be prepared to wait. Most of my local stores are booked for days. And just because you have an appointment doesn’t mean you’ll get your replacement right away. I went in to Apple’s San Francisco flagship five days after its announcement and my store Genius reported he was already out of stock of iPhone 6 batteries — and there were thousands of other customers ahead of me to get one. They’ll email me when there’s a battery in stock, at which point I have to go back to the store.
Apple could improve this process. As my Genius explained it, you can’t get in the queue for a replacement battery until a Genius has signed off on your order — so there’s no way to avoid two trips. And there’s also no way to easily check stock supplies; when I tried calling another store, I couldn’t get a straight answer. If Apple can’t meet customer demand for replacements, it ought to at least help set our expectations.
There are a few other options. If you live far away from a store and have a backup phone handy, you could mail your iPhone to Apple to replace the battery, via the same Apple support site. (There’s also a $7 shipping fee.)
You could take the unofficial route. A service called iCracked will send a repair person to you to replace a battery for between $20 and $50. Some mom-and-pop repair shops will replace an iPhone battery for less than $30.
Or there is the hands-on approach: Buy a battery replacement kit, like the $25 one sold by iFixit. This isn’t for the clumsy or fainthearted, but there’s a special satisfaction to opening up a gadget and seeing what makes it tick … and then ripping it out and replacing it with something better.
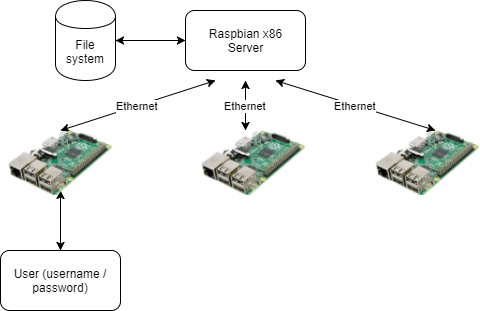
As Simon mentioned in his recent blog post about Raspbian Stretch, we have developed a new piece of software called PiServer. Use this tool to easily set up a network of client Raspberry Pis connected to a single x86-based server via Ethernet. With PiServer, you don’t need SD cards, you can control all clients via the server, and you can add and configure user accounts — it’s ideal for the classroom, your home, or an industrial setting.
Client? Server?
Before I go into more detail, let me quickly explain some terms.
Server — the server is the computer that provides the file system, boot files, and password authentication to the client(s)
Client — a client is a computer that retrieves boot files from the server over the network, and then uses a file system the server has shared. More than one client can connect to a server, but all clients use the same file system.
User – a user is a user name/password combination that allows someone to log into a client to access the file system on the server. Any user can log into any client with their credentials, and will always see the same server and share the same file system. Users do not have sudo capability on a client, meaning they cannot make significant changes to the file system and software.
I see no SD cards
Last year we described how the Raspberry Pi 3 Model B can be booted without an SD card over an Ethernet network from another computer (the server). This is called network booting or PXE (pronounced ‘pixie’) booting.
Why would you want to do this?
A client computer (the Raspberry Pi) doesn’t need any permanent storage (an SD card) to boot.
You can network a large number of clients to one server, and all clients are exactly the same. If you log into one of the clients, you will see the same file system as if you logged into any other client.
The server can be run on an x86 system, which means you get to take advantage of the performance, network, and disk speed on the server.
Sounds great, right? Of course, for the less technical, creating such a network is very difficult. For example, there’s setting up all the required DHCP and TFTP servers, and making sure they behave nicely with the rest of the network. If you get this wrong, you can break your entire network.
PiServer to the rescue
To make network booting easy, I thought it would be nice to develop an application which did everything for you. Let me introduce: PiServer!
PiServer has the following functionalities:
It automatically detects Raspberry Pis trying to network boot, so you don’t have to work out their Ethernet addresses.
It sets up a DHCP server — the thing inside the router that gives all network devices an IP address — either in proxy mode or in full IP mode. No matter the mode, the DHCP server will only reply to the Raspberry Pis you have specified, which is important for network safety.
It creates user names and passwords for the server. This is great for a classroom full of Pis: just set up all the users beforehand, and everyone gets to log in with their passwords and keep all their work in a central place. Moreover, users cannot change the software, so educators have control over which programs their learners can use.
It uses a slightly altered Raspbian build which allows separation of temporary spaces, doesn’t have the default ‘pi’ user, and has LDAP enabled for log-in.
What can I do with PiServer?
SERVE A WHOLE CLASSROOM OF PIS
In a classroom, PiServer allows all files for lessons or projects to be stored on a central x86-based computer. Each user can have their own account, and any files they create are also stored on the server. Moreover, the networked Pis doesn’t need to be connected to the internet. The teacher has centralised control over all Pis, and all Pis are user-agnostic, meaning there’s no need to match a person with a computer or an SD card.
BUILD A HOME SERVER
PiServer could be used in the home to serve file systems for all Raspberry Pis around the house — either a single common Raspbian file system for all Pis or a different operating system for each. Hopefully, our extensive OS suppliers will provide suitable build files in future.
USE IT AS A CONTROLLER FOR NETWORKED PIS
In an industrial scenario, it is possible to use PiServer to develop a network of Raspberry Pis (maybe even using Power over Ethernet (PoE)) such that the control software for each Pi is stored remotely on a server. This enables easy remote control and provisioning of the Pis from a central repository.
How to use PiServer
THE CLIENT MACHINES
So that you can use a Pi as a client, you need to enable network booting on it. Power it up using an SD card with a Raspbian Lite image, and open a terminal window. Type in
echo program_usb_boot_mode=1| sudo tee -a /boot/config.txt
and press Return. This adds the line program_usb_boot_mode=1 to the end of the config.txt file in /boot. Now power the Pi down and remove the SD card. The next time you connect the Pi to a power source, you will be able to network boot it.
THE SERVER MACHINE
As a server, you will need an x86 computer on which you can install x86 Debian Stretch. Refer to Simon’s blog post for additional information on this. It is possible to use a Raspberry Pi to serve to the client Pis, but the file system will be slower, especially at boot time.
Make sure your server has a good amount of disk space available for the file system — in general, we recommend at least 16Gb SD cards for Raspberry Pis. The whole client file system is stored locally on the server, so the disk space requirement is fairly significant.
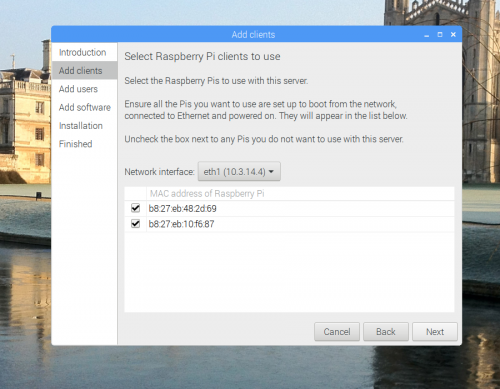
Next, start PiServer by clicking on the start icon and then clicking Preferences >PiServer. This will open a graphical user interface — the wizard — that will walk you through setting up your network. Skip the introduction screen, and you should see a screen looking like this:
If you’ve enabled network booting on the client Pis and they are connected to a power source, their MAC addresses will automatically appear in the table shown above. When you have added all your Pis, click Next.
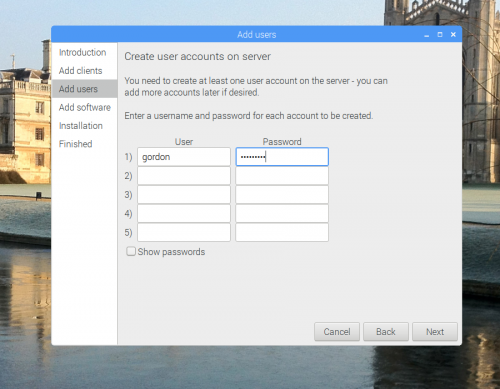
On the Add users screen, you can set up users on your server. These are pairs of user names and passwords that will be valid for logging into the client Raspberry Pis. Don’t worry, you can add more users at any point. Click Next again when you’re done.
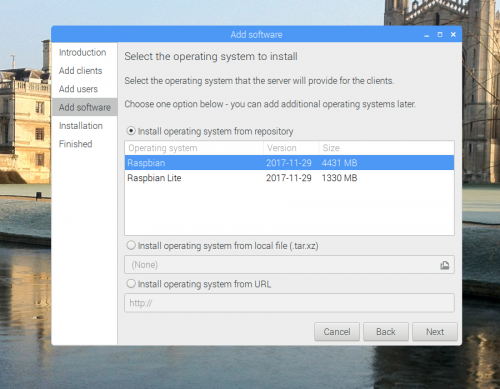
The Add software screen allows you to select the operating system you want to run on the attached Pis. (You’ll have the option to assign an operating system to each client individually in the setting after the wizard has finished its job.) There are some automatically populated operating systems, such as Raspbian and Raspbian Lite. Hopefully, we’ll add more in due course. You can also provide your own operating system from a local file, or install it from a URL. For further information about how these operating system images are created, have a look at the scripts in /var/lib/piserver/scripts.
Once you’re done, click Next again. The wizard will then install the necessary components and the operating systems you’ve chosen. This will take a little time, so grab a coffee (or decaffeinated drink of your choice).
When the installation process is finished, PiServer is up and running — all you need to do is reboot the Pis to get them to run from the server.
Shooting troubles
If you have trouble getting clients connected to your network, there are a fewthings you can do to debug:
If some clients are connecting but others are not, check whether you’ve enabled the network booting mode on the Pis that give you issues. To do that, plug an Ethernet cable into the Pi (with the SD card removed) — the LEDs on the Pi and connector should turn on. If that doesn’t happen, you’ll need to follow the instructions above to boot the Pi and edit its /boot/config.txt file.
If you can’t connect to any clients, check whether your network is suitable: format an SD card, and copy bootcode.bin from /boot on a standard Raspbian image onto it. Plug the card into a client Pi, and check whether it appears as a new MAC address in the PiServer GUI. If it does, then the problem is a known issue, and you can head to our forums to ask for advice about it (the network booting code has a couple of problems which we’re already aware of). For a temporary fix, you can clone the SD card on which bootcode.bin is stored for all your clients.
If neither of these things fix your problem, our forums are the place to find help — there’s a host of people there who’ve got PiServer working. If you’re sure you have identified a problem that hasn’t been addressed on the forums, or if you have a request for a functionality, then please add it to the GitHub issues.
Brain “listens” to itself, re-balances its brainwave activity between hemispheres
January 3, 2018
Patient receiving a real-time reflection of her frontal-lobe brainwave activity as a stream of audio tones through earbuds. (credit: Brain State Technologies)
You are relaxing comfortably, eyes closed, with non-invasive sensors attached to your scalp that are picking up signals from various areas of your brain. The signals are converted by a computer to audio tones that you can hear on earbuds. Over several sessions, the different frequencies (pitches) of the tones associated with the two hemispheres of the brain create a mirror for your brainwave activity, helping your brain reset itself to reduce traumatic stress.
In a study conducted at Wake Forest School of Medicine, 20 sessions of noninvasive brainwave “mirroring” neurotechnology called HIRREM* (high-resolution, relational, resonance-based electroencephalic mirroring) significantly reduced symptoms of post-traumatic stress resulting from service as a military member or vet.
“We observed reductions in post-traumatic symptoms**, including insomnia, depressive mood, and anxiety, that were durable through six months after the use of HIRREM, but additional research is needed to confirm these initial findings,” said the study’s principal investigator, Charles H. Tegeler, M.D., professor of neurology at Wake Forest School of Medicine, a part of Wake Forest Baptist.
About 500 patients have participated in HIRREM clinical trials at Wake Forest School of Medicine and other locations, according to Brain State Technologies Founder and CEO Lee Gerdes.
Brain State Technologies | HIRREM process, showing a technologist applying Brain State Technologies’ proprietary HIRREM process with a military veteran client.
HIRREM is intended for medical research. A consumer version of the core underlying brainwave mirroring process is available as “Brainwave Optimization” from Brain State Technologies in Scottsdale, Arizona. The company also offers a wearable device for ongoing brain support, BRAINtellect B2v2.
How HIRREM neurotechnology works
(credit: Brain State Technologies)
HIRREM is a neurotechnology that dynamically measures brain electrical activity. It uses two or more EEG (electroencephalogram, or brain-wave detection) scalp sensors to pick up signals from both sides of the brain. Computer software algorithms then convert dominant brain frequencies in real time into audible tones with varying pitch and timing, which can be heard on earbuds.
In effect, the brain is listening to itself. It the process, it makes self-adjustments towards improved balance (between brain temporal lobe activity in the two hemispheres — sympathetic (right) and parasympathetic (left) — of the brain), resulting in reduced hyper-arousal. No conscious cognitive activity is required. Signals from other areas of the brain can also be studied.
The net effect is to reset stress response patterns that have been wired by repetitive traumatic events (physical or non-physical).***
The study was published (open access) in the Dec. 22 online edition of the journal Military Medical Research with co-authors at Brain State Technologies. It was supported through the Joint Capability Technology Demonstration Program within the Office of the Under Secretary of Defense and by a grant from The Susanne Marcus Collins Foundation, Inc. to the Department of Neurology at Wake Forest Baptist.
The researchers acknowledge limitations of the study, including the small number of participants and the absence of a control group. It was also an open-label project, meaning that both researchers and participants knew what treatment was being administered.
* HIRREM is a registered trademark of Brain State Technologies based in Scottsdale, Arizona, and has been licensed to Wake Forest University for collaborative research since 2011. In this single-site study, 18 service members or recent veterans, who experienced symptoms over one to 25 years, received an average of 19½ HIRREM sessions over 12 days. Symptom data were collected before and after the study sessions, and follow-up online interviews were conducted at one-, three- and six-month intervals. In addition, heart rate and blood pressure readings were recorded after the first and second visits to analyze downstream autonomic balance with heart rate variability and baroreflex sensitivity. HIRREMhas been used experimentally with more than 500 patients at Wake Forest School of Medicine.
** According to the U.S. Department of Veterans Affairs, approximately 31 percent of Vietnam veterans, 10 percent of Gulf War (Desert Storm) veterans and 11 percent of veterans of the war in Afghanistan experience PTSD. Symptoms can include insomnia, poor concentration, sadness, re-experiencing traumatic events, irritability or hyper-alertness, and diminished autonomic cardiovascular regulation.
*** The effect is based on the “bihemispheric autonomic model” (BHAM ), “which proposes that trauma-related sympathetic hyperarousal may be an expression of maladaptive right temporal lobe activity, whereas the avoidant and dissociative features of the traumatic stress response may be indicators of a parasympathetic “freeze” response that is significantly driven by the left temporal lobe. An implication [is that brain-based] intervention may facilitate the reduction of symptom clusters associated with autonomic disturbances through the mitigation of maladaptive asymmetries.” — Catherine L. Tegeler et al./Military Medical Research.
Abstract of Successful use of closed-loop allostatic neurotechnology for post-traumatic stress symptoms in military personnel: self-reported and autonomic improvements
Background: Military-related post-traumatic stress (PTS) is associated with numerous symptom clusters and diminished autonomic cardiovascular regulation. High-resolution, relational, resonance-based, electroencephalic mirroring (HIRREM®) is a noninvasive, closed-loop, allostatic, acoustic stimulation neurotechnology that produces real-time translation of dominant brain frequencies into audible tones of variable pitch and timing to support the auto-calibration of neural oscillations. We report clinical, autonomic, and functional effects after the use of HIRREM® for symptoms of military-related PTS.
Methods: Eighteen service members or recent veterans (15 active-duty, 3 veterans, most from special operations, 1 female), with a mean age of 40.9 (SD = 6.9) years and symptoms of PTS lasting from 1 to 25 years, undertook 19.5 (SD = 1.1) sessions over 12 days. Inventories for symptoms of PTS (Posttraumatic Stress Disorder Checklist – Military version, PCL-M), insomnia (Insomnia Severity Index, ISI), depression (Center for Epidemiologic Studies Depression Scale, CES-D), and anxiety (Generalized Anxiety Disorder 7-item scale, GAD-7) were collected before (Visit 1, V1), immediately after (Visit 2, V2), and at 1 month (Visit 3, V3), 3 (Visit 4, V4), and 6 (Visit 5, V5) months after intervention completion. Other measures only taken at V1 and V2 included blood pressure and heart rate recordings to analyze heart rate variability (HRV) and baroreflex sensitivity (BRS), functional performance (reaction and grip strength) testing, blood and saliva for biomarkers of stress and inflammation, and blood for epigenetic testing. Paired t-tests, Wilcoxon signed-rank tests, and a repeated-measures ANOVA were performed.
Results: Clinically relevant, significant reductions in all symptom scores were observed at V2, with durability through V5. There were significant improvements in multiple measures of HRV and BRS [Standard deviation of the normal beat to normal beat interval (SDNN), root mean square of the successive differences (rMSSD), high frequency (HF), low frequency (LF), and total power, HF alpha, sequence all, and systolic, diastolic and mean arterial pressure] as well as reaction testing. Trends were seen for improved grip strength and a reduction in C-Reactive Protein (CRP), Angiotensin II to Angiotensin 1–7 ratio and Interleukin-10, with no change in DNA n-methylation. There were no dropouts or adverse events reported.
Conclusions: Service members or veterans showed reductions in symptomatology of PTS, insomnia, depressive mood, and anxiety that were durable through 6 months after the use of a closed-loop allostatic neurotechnology for the auto-calibration of neural oscillations. This study is the first to report increased HRV or BRS after the use of an intervention for service members or veterans with PTS. Ongoing investigations are strongly warranted.
This is the first in a series of posts about the Singularity, that notional future time when machine intelligence explodes in capability, changing human life forever. Like many computer scientists, I’m a Singularity skeptic. In this series I’ll be trying to express the reasons for my skepticism–and workshopping ideas for an essay on the topic that I’m working on. Your comments and feedback are even more welcome that usual!
What is the Singularity? It is a notional future moment when technological change will be so rapid that we have no hope of understanding its implications. The Singularity is seen as a cultural event horizon beyond which humanity will become … something else that we cannot hope to predict. Singularity talk often blends into theories about future superintelligence posing an existential risk to humanity.
The essence of Singularity theory was summarized in an early (1965) paper by the British mathematician I.J. Good:
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an ‘intelligence explosion,’ and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control.
Vernor Vinge was the first to describe this as a “singularity”, adopting a term from mathematics that applies when the growth rate of a quantity goes to infinity. The term was further popularized by Ray Kurzweil’s book, “The Singularity is Near.”
Exponential Growth
The Singularity theory is fundamentally a claim about the future growth rate of machine intelligence. Before evaluating that claim, let’s first review some concepts useful for thinking about growth rates.
A key concept is exponential growth, which means simply that the increase in something is proportional to how big that thing already is. For example, if my bank account grows at 1% annually, this means that the every year the bank will add to my account 1% of the current balance. That’s exponential growth.
Exponential growth can happen at different speeds. There are two natural ways to characterize the speed of exponential growth. The first is a growth rate, typically stated as a percentage per some time unit. For example, my notional bank account has a growth rate of 1% per year. The second natural measure is the doubling time–how long it will take the quantity to double. For my bank account, that works out to about 70 years.
A good way to tell if a quantity is growing exponentially is to look at how its growth is measured. If the natural measure is a growth rate in percent per time, or a doubling time, then that quantity is growing exponentially. For example, economic growth in most countries is measured as a percent increase in (say) GDP, which tells us that GDP tends to grow exponentially over the long term–with short-term ups and downs, of course. If a country’s GDP is growing at 3% per year, that corresponds to a doubling time of about 23 years.
Exponential growth is very common in nature and in human society. So the fact that a quantity is growing exponentially does not in itself make that quantity special nor does it give that quantity unusual, counterintuitive dynamics.
The speed and capacity of computers has grown exponentially, which is not remarkable. What is remarkable is the growth rate in computing capacity. A rule of thumb called “Moore’s Law” states that the speed and capacity of computers will have a doubling time of 18 months, which corresponds to a growth rate of 60% per year. Moore’s Law has held true for roughly fifty years–that’s 33 doublings, or roughly a ten-billion-fold increase in capacity.
The Singularity is Not a Literal Singularity
As a first step in considering the plausibility of the Singularity hypothesis, let’s consider the prospect of a literal singularity–where the rate of improvement in machine intelligence literally becomes infinite at some point in the future. This requires that machine intelligence grows faster than any exponential, so that the doubling time gets smaller and smaller, and eventually goes to zero.
I don’t know of any theoretical basis for expecting a literal singularity. There is virtually nothing in the natural or human world that grows super-exponentially over time–and even “ordinary” super-exponential growth does not yield a literal singularity. In short, it’s hard to see how the AI “Singularity” could possibly be a true mathematical singularity.
So if the Singularity is not literally a singularity, what is it? The next post will start with that question.
Amazon could soon play ads to users shopping with Alexa, says report
Up here in the Great White North, the ability to make purchases on Amazon through Alexa is brand new, given that the Echo only just recently launched in Canada. In the U.S. though, this functionality has been around for a few years. With the Echo expanding to more regions, Amazon might have plans to place ads within its voice-activated Alexa speaker, according CNBC’s sources. Amazon has reportedly been in talks with Procter & Gamble and Clorox, in an effort to locate companies willing to pay to have their products placed higher in Alexa’s search results. Alexa might also soon advertise related products to users who previously bought specific items. This is similar to how the retail platform currently recommends products on the web. Sources report that Alexa could also suggest a specific brand’s products when a user asks for help performing a task, like cleaning up an accidental spill. It’s worth noting that Amazon’s current rules limit what types of ads can be delivered to users through Alexa. “Streaming music, streaming radio, podcast, and flash briefing skills may include audio advertisements as long as (1) the advertisements do not use Alexa’s voice or a similar voice, refer to Alexa, or imitate Alexa interactions and (2) the skill does not include more or materially different advertising than is included when the same or similar content is made available outside of Alexa,” reads an excerpt from a May 19th, 2017 Amazon Alexa blog post. Last year, a company called VoiceLabs made an effort to begin monetizing specific Alexa Skills, but the above policy shift forced it to stop selling sponsored messages. To Amazon’s credit, a spokesperson has denied CNBC‘s claims, stating that the company has no plans to bring advertisements to Alexa, according to a statement sent to Engadget. Given that voice-activated assistants like Google Assistant, Apple’s Siri and Samsung’s Bixby are viewed as the future of how consumers will interact with tech devices, ad placement potential is surely an exciting proposition for advertisers. From the perspective of someone who frequently utilizes devices like Alexa and Google Home to control smart home devices, I hope that when ads inevitably make their way to these devices, they’re not overly intrusive. I don’t look forward to the possibility of a Black Mirror-like dystopian future where asking Alexa to turn on my lights results in a 30-second Philips Hue smart lightbulb pre-roll.
tl;dr: there is presently an embargoed security bug impacting apparently all contemporary CPU architectures that implement virtual memory, requiring hardware changes to fully resolve. Urgent development of a software mitigation is being done in the open and recently landed in the Linux kernel, and a similar mitigation began appearing in NT kernels in November. In the worst case the software fix causes huge slowdowns in typical workloads. There are hints the attack impacts common virtualization environments including Amazon EC2 and Google Compute Engine, and additional hints the exact attack may involve a new variant of Rowhammer.
I don’t really care much for security issues normally, but I adore a little intrigue, and it seems anyone who would normally write about these topics is either somehow very busy, or already knows the details and isn’t talking, which leaves me with a few hours on New Years’ Day to go digging for as much information about this mystery as I could piece together.
Beware this is very much a connecting-the-invisible-dots type affair, so it mostly represents guesswork until such times as the embargo is lifted. From everything I’ve seen, including the vendors involved, many fireworks and much drama is likely when that day arrives.
LWN
The trail begins with LWN’s current state of kernel page-table isolation article posted on December 20th. It’s apparent from the tone that a great deal of urgent work by the core kernel developers has been poured into the KAISER patch series first posted in October by a group of researchers from TU Graz in Austria.
The purpose of the series is conceptually simple: to prevent a variety of attacks by unmapping as much of the Linux kernel from the process page table while the process is running in user space, greatly hindering attempts to identify kernel virtual address ranges from unprivileged userspace code.
The group’s paper describing KAISER, KASLR is Dead: Long Live KASLR, makes specific reference in its abstract to removing all knowledge of kernel address space from the memory management hardware while user code is active on the CPU.
Of particular interest with this patch set is that it touches a core, wholly fundamental pillar of the kernel (and its interface to userspace), and that it is obviously being rushed through with the greatest priority. When reading about memory management changes in Linux, usually the first reference to a change happens long before the change is ever merged, and usually after numerous rounds of review, rejection and flame war spanning many seasons and moon phases.
The KAISER (now KPTI) series was merged in some time less than 3 months.
Recap: ASLR
On the surface, the patches appear designed to ensure Address Space Layout Randomization remains effective: this is a security feature of modern operating systems that attempts to introduce as many random bits as possible into the address ranges for commonly mapped objects.
For example, on invoking /usr/bin/python, the dynamic linker will arrange for the system C library, heap, thread stack and main executable to all receive randomly assigned address ranges:
Notice how the start and end offset for the bash process heap changes across runs.
The effect of this feature is that, should a buffer management bug lead to an attacker being able to overwrite some memory address pointing at program code, and that address should later be used in program control flow, such that the attacker can divert control flow to a buffer containing contents of their choosing, it becomes much more difficult for the attacker to populate the buffer with machine code that would lead to, for example, the system() C library function being invoked, as the address of that function varies across runs.
This is a simple example, ASLR is designed to protect many similar such scenarios, including preventing the attacker from learning the addresses of program data that may be useful for modifying control flow or implementing an attack.
KASLR is “simply” ASLR applied to the kernel itself: on each reboot of the system, address ranges belonging to the kernel are randomized such that an attacker who manages to divert control flow while running in kernel mode cannot guess addresses for functions and structures necessary for implementing their attack, such as locating the current process data, and flipping the active UID from an unprivileged user to root, etc.
Bad news: the software mitigation is expensive
The primary reason for the old Linux behaviour of mapping kernel memory in the same page tables as user memory is so that when the user’s code triggers a system call, fault, or an interrupt fires, it is not necessary to change the virtual memory layout of the running process.
Since it is unnecessary to change the virtual memory layout, it is further unnecessary to flush highly performance-sensitive CPU caches that are dependant on that layout, primarily the Translation Lookaside Buffer.
With the page table splitting patches merged, it becomes necessary for the kernel to flush these caches every time the kernel begins executing, and every time user code resumes executing. For some workloads, the effective total loss of the TLB lead around every system call leads to highly visible slowdowns: @grsecurity measured a simple case where Linux “du -s” suffered a 50% slowdown on a recent AMD CPU.
34C3
Over at this year’s CCC, you can find another of the TU Graz researchers describing a pure-Javascript ASLR attack that works by carefully timing the operation of the CPU memory management unit as it traverses the page tables that describe the layout of virtual memory. The effect is that through a combination of high precision timing and selective eviction of CPU cache lines, a Javascript program running in a web browser can recover the virtual address of a Javascript object, enabling subsequent attacks against browser memory management bugs.
So again, on the surface, we have a group authoring the KAISER patches also demonstrating a technique for unmasking ASLR’d addresses, and the technique, demonstrated using Javascript, is imminently re-deployable against an operating system kernel.
Recap: Virtual Memory
In the usual case, when some machine code attempts to load, store, or jump to a memory address, modern CPUs must first translate this virtual address to a physical address, by way of walking a series of OS-managed arrays (called page tables) that describe a mapping between virtual memory and physical RAM installed in the machine.
Virtual memory is possibly the single most important robustness feature in modern operating systems: it is what prevents, for example, a dying process from crashing the operating system, a web browser bug crashing your desktop environment, or one virtual machine running in Amazon EC2 from effecting changes to another virtual machine on the same host.
The attack works by exploiting the fact that the CPU maintains numerous caches, and by carefully manipulating the contents of these caches, it is possible to infer which addresses the memory management unit is accessing behind the scenes as it walks the various levels of page tables, since an uncached access will take longer (in real time) than a cached access. By detecting which elements of the page table are accessed, it is possible to recover the majority of the bits in the virtual address the MMU was busy resolving.
Evidence for motivation, but not panic
We have found motivation, but so far we have not seen anything to justify the sheer panic behind this work. ASLR in general is an imperfect mitigation and very much a last line of defence: there is barely a 6 month period where even a non-security minded person can read about some new method for unmasking ASLR’d pointers, and reality has been this way for as long as ASLR has existed.
Fixing ASLR alone is not sufficient to describe the high priority motivation behind the work.
Evidence: it’s a hardware security bug
From reading through the patch series, a number of things are obvious.
First of all, as @grsecurity points out, some comments in the code have been redacted, and additionally the main documentation file describing the work is presently missing entirely from the Linux source tree.
Examining the code, it is structured in the form of a runtime patch applied at boot only when the kernel detects the system is impacted, using exactly the same mechanism that, for example, applies mitigations for the infamous Pentium F00F bug:
More clues: Microsoft have also implemented page table splitting
From a little digging through the FreeBSD source tree, it seems that so far other free operating systems are not implementing page table splitting, however as noted by Alex Ioniscu on Twitter, the work already is not limited to Linux: public NT kernels from as early as November have begun to implement the same technique.
In this paper, we present novel Rowhammer attack and exploitation primitives, showing that even a combination of all defenses is ineffective. Our new attack technique, one-location hammering, breaks previous assumptions on requirements for triggering the Rowhammer bug
As a quick recap, Rowhammer is a class of problem fundamental to most (all?) kinds of commodity DRAMs, such as the memory in the average computer. Through precise manipulation of one area of memory, it is possible to cause degradation of storage in a related (but otherwise logically distinct) area of memory. The effect is that Rowhammer can be used to flip bits of memory that unprivileged user code should have no access to, such as bits describing how much access that code should have to the rest of the system.
I found this work on Rowhammer particularly interesting, not least for its release being in such close proximity to the page table splitting patches, but because Rowhammer attacks require a target: you must know the physical address of the memory you are attempting to mutate, and a first step to learning a physical address may be learning a virtual address, such as in the KASLR unmasking work.
Guesswork: it effects major cloud providers
On the kernel mailing list we can see, in addition to the names of subsystem maintainers, e-mail addresses belonging to employees of Intel, Amazon and Google. The presence of the two largest cloud providers is particularly interesting, as this provides us with a strong clue that the work may be motivated in large part by virtualization security.
Which leads to even more guessing: virtual machine RAM, and the virtual memory addresses used by those virtual machines are ultimately represented as large contiguous arrays on the host machine, arrays that, especially in the case of only 2 tenants on a host machine, are assigned by memory allocators in the Xen and Linux kernels that likely have very predictable behaviour.
Favourite guess: it is a privilege escalation attack against hypervisors
Putting it all together, I would not be surprised if we start 2018 with the release of the mother of all hypervisor privilege escalation bugs, or something similarly systematic as to drive so much urgency, and the presence of so many interesting names on the patch set’s CC list.
One final tidbit, while I’ve lost my place reading through the patches, there is some code that specifically marked either paravirtual or HVM Xen as unaffected.
Invest in popcorn, 2018 is going to be fun
It’s totally possible this guess is miles off reality, but one thing is for sure, it’s going to be an exciting few weeks when whatever this thing is published.
Picking out sick people just by looking at their faces
Jan 3, 2018
Stat News reported on a new study out of Sweden that suggests humans can detect whether someone is sick by looking at their faces.
UBC psychology professor Mark Schaller, who wasn’t involved in the study, said the ratio of false alarms was quite high, and that the observers were only semi-accurate.
“It’s a useful reminder of the fact that when we humans use superficial characteristics as sickness cues … those superficial features often lead us astray, with the consequence that we may often respond to healthy people as though they are sick,” said Schaller.
Artist’s depiction of the “Ancient Beringians” and their Upward Sun River base camp. (Credit: Eric S. Carlson in collaboration with Ben Potter)
She died 11,500 years ago at the tender age of six weeks in what is now the interior of Alaska. Dubbed “Sunrise Girl-child” by the local indigenous people, the remains of the Ice Age infant—uncovered at an archaeological dig in 2013—contained traces of DNA, allowing scientists to perform a full genomic analysis. Incredibly, this baby girl belonged to a previously unknown population of ancient Native Americans—a discovery that’s changing what we know about the continent’s first people.
Genetic evidence published today in Nature is the first to show that all Native Americans can trace their ancestry back to a single migration event that happened at the tail-end of the last Ice Age. The evidence—gleaned from the full genomic profile of the six-week-old girl and the partial genomic remains of another infant—suggests the continent’s first settlers arrived in a single migratory wave around 20,900 years ago. But this population then split into two groups—one group that would go on to become the ancestors of all Native North Americans, and another that would venture no further than Alaska—a previously unknown population of ancient North Americans now dubbed the “Ancient Beringians.”
It’s well established that North America’s first settlers migrated from Siberia into Alaska prior to the end of the last Ice Age via an ancient land bridge known as Beringia (actually, the term “bridge” is a bit of a misnomer as Beringia was a sizeable landmass measuring 620 miles (1,000 km) at its widest extent and encompassing an area as large as the Canadian provinces of British Columbia and Alberta combined; those humans living and venturing across this landmass would hardly think of it as a “bridge”). But scientists aren’t sure if there was a single founding group or several, or when the migration actually happened.
Archaeologists working at the Upward Sun River site in Alaska. (Image: Ben Potter)
The remains of two human infants, found at the Upward Sun River (USR) site in the Alaskan interior, are changing what we know of this important period in human history. The researchers who conducted the genetic analysis, which involved teams from the University of Cambridge, the University of Copenhagen, and the University of Alaska Fairbanks, were fully expecting the USR DNA to match the genetic profiles of other northern Native American people—but it matched no other known ancient population, not even the two recognized branches of early indigenous peoples, known as Northern and Southern. It also didn’t match any contemporary human populations.
“We didn’t know this population existed,” said Ben Potter, professor of anthropology at the University of Alaska Fairbanks and a lead author of the new study, in a statement. “These data also provide the first direct evidence of the initial founding Native American population, which sheds new light on how these early populations were migrating and settling throughout North America.”
Genetic analysis showed that these Ancient Beringians were more closely related to early Native Americans than their Asian and Eurasian ancestors. Even though the DNA extracted from the second infant wasn’t able to produce a full genome for analysis, the researchers were able to determine that the two girls belonged to the same population. The genetic analysis, combined with computer-based population modeling, allowed the researchers to conclude that a single founding ancestral indigenous American group split from East Asians around 35,000 years ago. Then, around 20,000 years ago, this group split into two groups: the ancestors of all Native Americans, and the Ancient Beringians.
Discovery and excavation of the Upward Sun River infants. (Credit: Ben Potter)
“The Ancient Beringians diversified from other Native Americans before any ancient or living Native American population sequenced to date. It’s basically a relict population of an ancestral group which was common to all Native Americans, so the sequenced genetic data gave us enormous potential in terms of answering questions relating to the early peopling of the Americas,” said lead author Eske Willerslev, who holds positions at both the University of Cambridge and the University of Copenhagen. “We were able to show that people probably entered Alaska before 20,000 years ago. It’s the first time that we have had direct genomic evidence that all Native Americans can be traced back to one source population, via a single, founding migration event.”
The discovery suggests two possible scenarios for the peopling of the Americas. Either two distinct groups of people crossed over Beringia prior to 15,700 years ago, or one group of people crossed over the land bridge and then split in Beringia into two groups, namely the Ancient Beringians and the Native Americans (where the latter moved south of the ice sheets 15,700 years ago). The study also reaffirms a pre-existing theory known as the “Standstill Model”—the possibility that the descendents of this single-source population were living in Beringia until about 11,500 years ago.
Regardless, it now appears that the Ancient Beringians stayed in the far North for thousands of years, while the ancestors of other Native American peoples spread throughout the rest of North America. The new genetic analysis, along with previous archaeological work, also lends credence to the idea that an offshoot of these migrants, known as the Athabascans, made their way back into the northern regions of North America again, possibly around 6,000 years ago (a process known as back migration), eventually absorbing or replacing the Ancient Beringians. More research will be required to bear this theory out.
“The differences between the genomes of the Upward Sun River infants and the genomes of other ancient Native Americans sets the Alaskan infants apart,” Gary Haynes, an anthropologist at the University of Nevada, told Gizmodo, “But there are also similarities which suggest that all the studied individuals are descendants of a single ancestral founding population. The USR population split after 20,900 years from the population that gave rise to all modern northern and southern Native Americans. The critical importance of this conclusion, if it is correct, is that it provides support for the view that a single founding population from Northeast Asia gave rise to all the native peoples of the Americas. This is a significant finding which establishes that all the pre-Columbian native peoples of the New World are members of one family tree.”
Haynes, who isn’t affiliated with the new study, says it’s important to keep in mind that the paper’s conclusions are based heavily on genetic analysis and that the authors weren’t able to provide empirical support in the form of archaeological evidence with firm dates.
“The suggested dating of population movements and genetic divergences in the paper relies on estimates of genetic rates of change, with tacit support from paleogeographic data (the existence of ice sheets at certain times, for example, blocking human movement), and the implication that archeological claims are correct about human presence [more than 15,000 years ago] in the Americas south of Beringia,” he said.
David Lambert, a professor at Griffith University’s Australian Research Centre for Human Evolution, says the study was “carefully conducted, and employed generally well understood laboratory… methods,” and that the research was of “a very high standard.” Lambert, who wasn’t involved in the new study, says the authors presented strong genomic evidence for a previously unknown but distinct early North American population.
“The conclusions are sound and it is clear that the results represent a significant new chapter in our understanding of the settlement of North America,” Lambert told Gizmodo. “The authors present evidence for a complex history of late Pleistocene genomic evolution that includes evidence for introversion [the spawning of new populations who keep to themselves], back migrations, and evidence of a single founding population that split from East Asians.”
Lambert is particularly stoked about the way ancient DNA is able to produce new and unexpected findings. “This study shows that even a single ancient genome sequenced to a good coverage can potentially make major contributions to our understanding of ancient complex histories,” he said.
Indeed, this study is dependent on a single—albeit really good—sample of DNA. It’s possible the infant could be some kind of a genetic outlier (an unlikely scenario given the similarities observed between the two USR infants). More genetic evidence of these Ancient Beringians, along with more archaeological evidence, will be required to affirm these findings and push this research forward. But it’s an exciting result nonetheless—one that paints more a more complex picture of how North America was settled.
 Apple Genius Bar employees assist customers at the company’s Fifth Avenue store in New York. (John Moore/Getty Images)
Apple Genius Bar employees assist customers at the company’s Fifth Avenue store in New York. (John Moore/Getty Images)