LaBSE: Language-Agnostic BERT Sentence Embedding by Google AI
How Google AI Pushed the Limits of Multi-lingual Sentence Embeddings to 109 Languages

Rohan JagtapFollowAug 26 · 5 min read
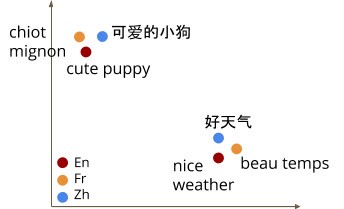
Multilingual Embedding Models are the ones that map text from multiple languages to a shared vector space (or embedding space). This implies that in this embedding space, related or similar words will lie closer to each other, and unrelated words will be distant (refer to the figure above).
In this article, we will discuss LaBSE: Language-Agnostic BERT Sentence Embedding, recently proposed in Feng et. al. which is the state of the art in Sentence Embedding.
Existing Approaches
The existing approaches mostly involve training the model on a large amount of parallel data. Models like LASER: Language-Agnostic SEntence Representations and m-USE: Multilingual Universal Sentence Encoder essentially map parallel sentences directly from one language to another to obtain the embeddings. They perform pretty well across a number of languages. However, they do not perform as good as dedicated bilingual modeling approaches such as Translation Ranking (which we are about to discuss). Moreover, due to limited training data (especially for low-resource languages) and limited model capacity, these models cease to support more languages.
Recent advances in NLP suggest training a language model on a masked language modeling (MLM) or a similar pre-training objective and then fine-tuning it on downstream tasks. Models like XLM are extended on the MLM objective, but on a cross-lingual setting. These work great on the downstream tasks but produce poor sentence-level embeddings due to the lack of a sentence-level objective.
Rather, the production of sentence embeddings from MLMs must be learned via fine-tuning, similar to other downstream tasks.
Language-Agnostic BERT Sentence Embedding
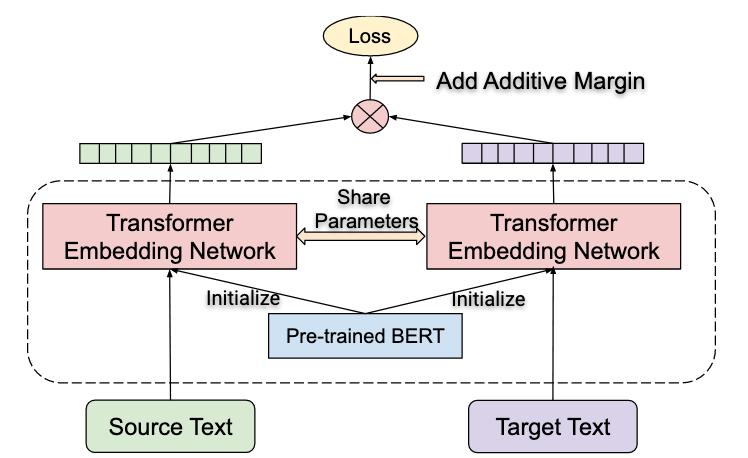
The proposed architecture is based on a Bidirectional Dual-Encoder (Guo et. al.) with Additive Margin Softmax (Yang et al.) with improvements. In the next few sub-sections we will decode the model in-depth:
Translation Ranking Task

First things first, Guo et. al. uses a translation ranking task which essentially ranks all the target sentences in order of their compatibility with the source. This is usually not ‘all’ the sentences but some ‘K – 1’ sentences. The objective is to maximize the compatibility between the source sentence and its real translation and minimize it with others (negative sampling).
Bidirectional Dual Encoder
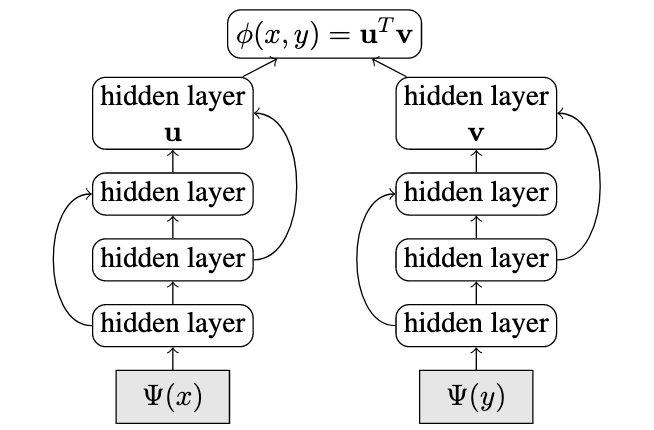
The dual-encoder architecture essentially uses parallel encoders to encode two sequences and then obtain a compatibility score between both the encodings using a dot-product. The model in Guo et. al. was essentially trained on a parallel corpus for the translation ranking task which was discussed in the previous section.
As far as ‘bidirectional’ is concerned; it basically takes the compatibility scores in both the ‘directions’, i.e. from source to target as well as from target to source. For example, if the compatibility from source x to target yis denoted by ɸ(x_i, y_i), then the score ɸ(y_i, x_i)is also taken into account and the individual losses are summed.
Loss = L + L′
Additive Margin Softmax (AMS)
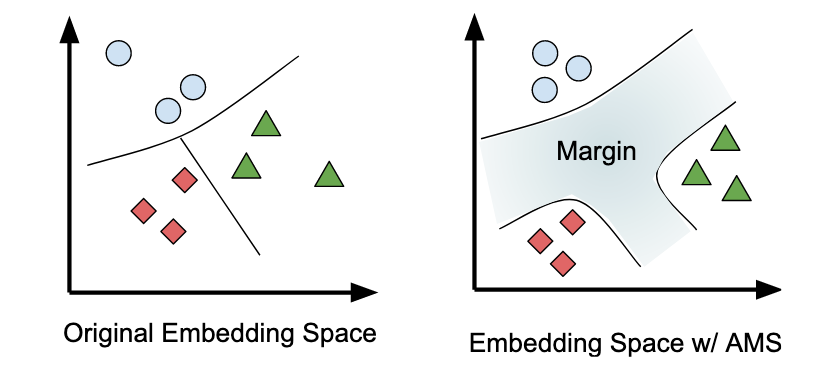
In vector spaces, classification boundaries can be pretty narrow, hence it can be difficult to separate the vectors. AMS suggests introducing a parameter min the original softmax loss to increase the separability between the vectors.

Notice how the parameter m is subtracted just from the positive sample and not the negative ones which is responsible for the classification boundary.
You can refer to this blog if you’re interested in getting a better understanding of AMS.
Cross-Accelerator Negative Sampling
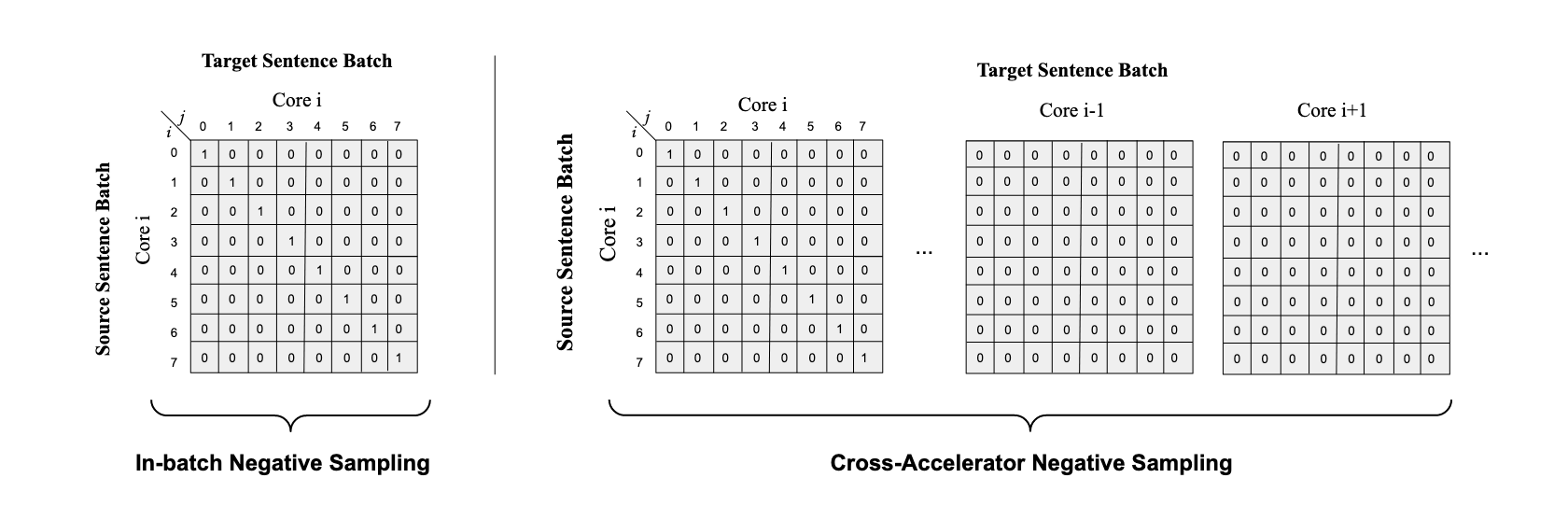
The translation ranking task suggests using negative sampling for ‘K – 1’ other sentences that aren’t potentially compatible translations of the source sentence. This is usually done by taking sentences from the rest of the batch. This in-batch negative sampling is depicted in the above figure (left). However, LaBSE leverages BERT as its encoder network. For heavy networks like these, it is infeasible to have batch sizes that are large enough to provide sufficient negative samples for training. Thus, the proposed approach leverages distributed training methods to share batches across different accelerators (GPUs) and broadcasting them in the end. Here, all the shared batches are considered as negative samples, and just the sentences in the local batch are considered for positive sampling. This is depicted in the above figure (right).
Pre-Training and Parameter Sharing
Finally, as mentioned earlier, the proposed architecture uses BERT encoders and are pretrained on Masked Language Model (MLM) as in Devlin et. al. and Translation Language Model (TLM) objective as in XLM (Conneau and Lample). Moreover, these are trained using a 3-stage progressive stacking algorithm i.e. an L layered encoder is first trained for L / 4 layers, then L / 2 layers and then finally L layers.
For more on BERT pre-training, you can refer to my blog.
Putting it All Together
LaBSE,
- combines all the existing approaches i.e. pre-training and fine-tuning strategies with bidirectional dual-encoder translation ranking model.
- is a massive model and supports 109 languages.
Results
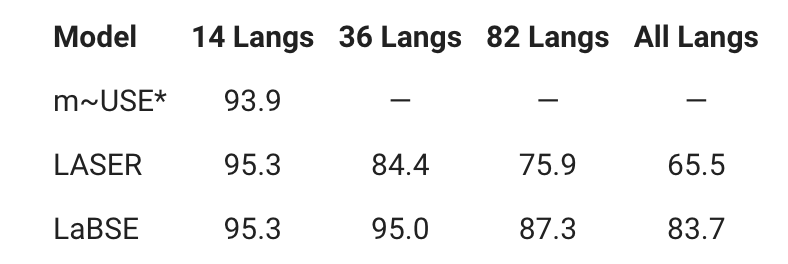
LaBSE clearly outperforms its competitors with a state of the art average accuracy of 83.7% on all languages.
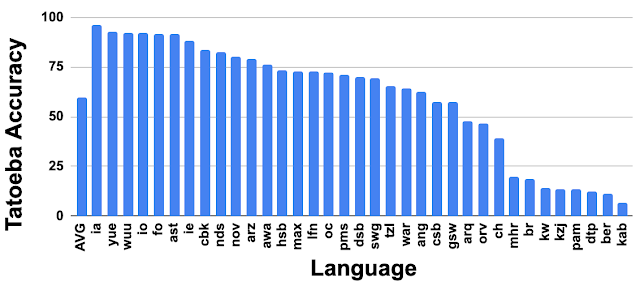
LaBSE was also able to produce decent results on the languages for which training data was not available (zero-shot).
Fun Fact: The model uses a 500k vocabulary size to support 109 languages and provides cross-lingual support for even zero-shot cases.
Conclusion
We discussed the Language-Agnostic BERT Sentence Embedding model and how pre-training approaches can be incorporated to obtain the state of the art sentence embeddings.
The model is open-sourced at TFHub here.
References
LaBSE Paper: https://arxiv.org/abs/2007.01852
Dual Encoders with AMS: https://www.ijcai.org/Proceedings/2019/746
Dual Encoders and Translation Ranking Task: https://www.aclweb.org/anthology/W18-6317/
XLM Paper: https://arxiv.org/abs/1901.07291BERT: Pre-Training of Transformers for Language UnderstandingUnderstanding Transformer-Based Self-Supervised Architecturesmedium.comAdditive Margin Softmax Loss (AM-Softmax)Understanding L-Softmax, A-Softmax, and AM-Softmaxtowardsdatascience.comTowards Data Science
A Medium publication sharing concepts, ideas, and codes.
Follow
