BRAIN STUDY REVEALS ONE TYPE OF EXERCISE INCREASES STRESS RESILIENCE
Exercise does a lot more than make you sweat. It helps you cope with stress down the line.ALI PATTILLO8.31.2020 10:30 AM
IN TIMES OF SERIOUS STRESS, people might turn to exercise to blow off steam and shake off nervous energy. However, despite anecdotal evidence, the link between working out and relieving stress isn’t well understood by scientists. Researchers haven’t yet pinned down exactly how exercise modulates stress in the brain and body, despite knowing that exercise benefits mental health.
In a recent study conducted in mice, researchers became one step closer to that understanding, discovering that exercise actually strengthens the brain’s resilience to stress. Exercise helps animals cope with stress by enabling an uptick in a crucial neural protein called galanin, the study suggests. This process influences stress levels, food consumption, cognition, and mood.
Leveraging this finding, researchers were able to genetically tweak even sedentary mice’s levels of galanin, shifts that lowered their anxious response to stress.
The study’s authors explain that this study helps pin down the biological mechanisms driving exercise’s positive effects on stress. While further human experiments are needed to confirm these findings, the researchers have practical advice for people looking to get these benefits: perform regular, aerobic exercise.
“Not exercising at all and then suddenly going for a hard 10 mile run just before a stressful event isn’t as helpful as regularly jogging 3 miles several days a week over several months,” researchers David Weinshenker and Rachel Tillage, tell Inverse by email.
That’s because, based on these results, a history of increased exercise doesn’t affect the immediate physiological response (like a release of cortisol) during a stressful event, Weinshenker and Tillage explain. Instead, exercise increases behavioral resilience after stress exposure.
“This could suggest that increased exercise doesn’t impact our immediate feelings of stress, but does allow us to cope with stress in a healthier way,” the co-authors say.
These findings were released Monday in the Journal of Neuroscience.
THE SEARCH FOR THE BRAIN MECHANISMS — Research shows exercise protects against the deleterious effects of stress in both mice and humans. Galanin, that pivotal brain protein that modulates stress and mood, is expressed in similar areas of both animal’s brains.
To examine how these factors interact and influence each other, the study team turned to mice.
“Mechanistic questions are difficult to answer in humans due to ethical and technical limitations, so we used mice for this purpose,” Weinshenker and Tillage say. With these overlapping properties, the team adds that the neurobiological substrates underlying galanin’s role in physical activity-related stress resilience could occur across species.
“ONE OF THE MAJOR IMPLICATIONS FROM THIS STUDY IN THAT THE GALANIN SYSTEM COULD BE A POTENTIAL TARGET FOR FUTURE THERAPIES… “
The measured mice’s anxious behavior 24 hours after a foot shock test — aka the stressful event. They also analyzed their levels of galanin and examined its source.
Half the mice had regular access to an exercise wheel in their cage, while others had no running wheel. Mice steadily increased their running distance over the first week, after which they ran approximately 10-16 kilometers per day. Researchers tracked the mice’s activity for three weeks.
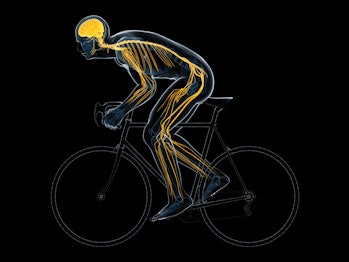
Aerobic exercise, like biking, is more likely to have a greater effect on stress resilience than non-aerobic exercise.Getty Images
Those who exercised showed less anxious behavior after the stressful event compared to mice that didn’t exercise. Exercising mice also had elevated galanin levels in the locus coeruleus, a cluster of neurons in the brainstem involved in the stress response.
The amount of time the mice spent exercising in the third week correlated with the amount of galanin in the locus coeruleus, which in turn correlated with their degree of stress resilience.
Based on these findings, the team then genetically increased galanin in the locus coeruleus in sedentary mice. This gave these inactive mice exercise’s beneficial stress resilience effects, without changing their physical activity patterns.
If further human experiments confirm these findings, it could mean hijacking the galanin system could help people gain exercise’s stress resilience benefits, even if they aren’t able to work out.
“These findings build on what we know by isolating a specific biological mechanism — increased galanin in the locus coeruleus— by which exercise can influence how we respond to stress,” Weinshenker and Tillage explain. “One of the major implications from this study in that the galanin system could be a potential target for future therapies to gain the positive effects of exercise on stress resilience for people who are not able to exercise.”
Interestingly, the increased galanin didn’t influence other aspects of the mice’s behavior, suggesting galanin may be recruited only during periods of high stress, the team says.
More human data is needed to figure out exactly what type or how much exercise confers this stress-resilience effect. But based on the current evidence, the researchers say they can offer some general guidance:
Aerobic exercise (like walking, running, biking, swimming) probably has a greater effect on stress resilience than non-aerobic exercise (like weight lifting).
Exercise probably needs to be routine; completed a few times a week. Cramming in a HIIT workout or long run right before a stressful event isn’t likely to be as helpful as regularly hiking or hitting the elliptical.
Abstract: The neuropeptide galanin has been implicated in stress-related neuropsychiatric disorders in humans and rodent models. While pharmacological treatments for these disorders are ineffective for many individuals, physical activity is beneficial for stress-related symptoms. Galanin is highly expressed in the noradrenergic system, particularly the locus coeruleus (LC), which is dysregulated in stress-related disorders and activated by exercise. Galanin expression is elevated in the LC by chronic exercise, and blockade of galanin transmission attenuates exercise-induced stress resilience. However, most research on this topic has been done in rats, so it is unclear whether the relationship between exercise and galanin is species-specific. Moreover, use of intracerebroventricular galanin receptor antagonists in prior studies precluded defining a causal role for LC-derived galanin specifically. Therefore, the goals of this study were twofold. First, we investigated whether physical activity (chronic wheel running) increases stress resilience and galanin expression in the LC of male and female mice. Next, we used transgenic mice that overexpress galanin in noradrenergic neurons (Gal OX) to determine how chronically elevated noradrenergic-derived galanin, alone, alters anxiogenic-like responses to stress. We found that three weeks of ad libitum access to a running wheel in their home cage increased galanin mRNA in the LC of mice, which was correlated with and conferred resilience to stress. The effects of exercise were phenocopied by galanin overexpression in noradrenergic neurons, and Gal OX mice were resistant to the anxiogenic effect of optogenetic LC activation. These findings support a role for chronically increased noradrenergic galanin in mediating resilience to stress.
The chip industry is making progress in multiple physical dimensions and with multiple architectural approaches, setting the stage for huge performance increases based on more modular and heterogeneous designs, new advanced packaging options, and continued scaling of digital logic for at least a couple more process nodes.
A number of these changes have been discussed in recent conferences. Individually, they are potentially significant. But taken as a whole, they point to some important trends as the benefits of device scaling dwindle and market needs change. Among them:
For high-performance applications, chips are being designed based upon much more limited data movement and near-memory computing. This can be seen in floor plans where I/Os are on the perimeter of the chip rather than in the center, an approach that will increase performance by reducing the distance that data needs to travel, and consequently lower the overall power consumption.
Scaling of digital logic will continue beyond 3nm using high-NA EUV, a variety of gate-all-around FETs (CFETs, nanosheet/nanowire FETs), and carbon nanotube devices. At the same time, reticle sizes will increase to allow more components to fit into a package, if not on a single die. Both moves will add substantially more real estate by shrinking features, allowing for greater compute density. In addition, scaling of SRAM will continue, and more layers will be added for high-bandwidth memory (HBM) modules and for 3D-NAND flash.
Designs are becoming both more modular and more heterogeneous, setting the stage for more customization and faster time to market. All of the major foundries and OSATs are now endorsing a chiplet strategy, and they are offering multiple options based upon price and performance requirements.
Some of this has been in the works for years, but much of the development has been piecemeal. There is no single industry roadmap anymore, which in the past has been used as a guide for how all the developments fit together. Work continues on all fronts in the absence of that roadmap, but it frequently is difficult to understand how the big picture is developing because not everything is moving in sync. For example, ASML was talking publicly about high-numerical aperture EUV, which replaces a flat lens with an anamorphic one, even before EUV was commercially viable. And companies such as ASE and Amkor have been working on multiple versions of fan-outs, 2.5D and 3D-ICs for the better part of this decade, even though the market for these packaging schemes are very different than initially thought.
There are many new developments on the horizon, as well. Major foundries such as TSMC, UMC, GlobalFoundries and Samsung are building advanced packaging capabilities into the backend of manufacturing. TSMC also is planning to add chiplets into the frontend using bump-less hybrid bonding, which it calls SoIC. All of these will likely require significant changes across the industry, from EDA tools to test and post-silicon monitoring.
How quickly all of these different elements come together is unclear. No one likes to be first, and at this point, it’s not obvious which of these approaches and technologies will win, or even whether they will compete with each other. But change is essential as the volume of data continues to grow. This is driving more customized solutions to process and utilize that data closer to the source, which includes some level of intelligence nearly everywhere.
In the past, solutions were developed around the most advanced hardware or software based on the assumption that the next process generation would add big improvements in performance. That no longer works. Scaling is becoming more difficult and expensive, and power/performance benefits of shrinking features are diminishing. In addition, one size no longer fits all. It can vary greatly depending upon where end customers are in the compute hierarchy — end point, edge, or cloud — and how data needs to be structured and prioritized. As a result, chipmakers have shifted their focus to new and more modular architectures that are capable of everything from massive simulations and training algorithms in the cloud, to weeding out useless image and streaming video data at the source.
Put in perspective, more processing needs to happen everywhere faster, and it needs to be done using the same or less power. In addition, systems need to be created faster, and they need the ability to change much more quickly as market needs evolve and algorithms continue to change.
Architectural shifts To make that happen, hardware architectures need to change. Chipmakers have seen this coming for some time. For example, IBM’s new Power 10 chip concentrates customized compute elements in the center of the chip and moves peripherals and I/O to the edges.
“Acceleration needs to get pushed into the processor core,” said Bill Starke, the chip’s chief architect, at the recent Hot Chips conference. “Around the chip perimeter are PHYs.” IBM also introduced pod-level clustering, and added a new microarchitecture to support all of this.
Fig. 1: IBM’s Power 10 chip (L., from Hot Chips 2020), with processing cores concentrated in the middle of the chip served by localized memory and shared L3, vs. Power 9 (R., from Hot Chips 2018) with off-chip interconnect in center. Source: IBM/Hot Chips 2018/20
Others are taking similar approaches. Intel introduced a new architecture based on internally-developed chiplets, which clusters modular processing elements together using its Embedded Multichip Interconnect Bridges to HBM modules. In addition, it has updated its latest server chip architecture to minimize data movement.
Fig. 2: Intel’s latest server processor architecture (R.) reduces movement of data compared to the previous generation (L.) Source: Intel/Hot Chips
Likewise, Tenstorrent, which makes AI systems, created a highly modular system that includes 120 self-contained cores connected with a 2D bi-directional torus NoC. “Every core progresses at its own pace,” according to Jasmina Vasiljevic, director of software engineering at Tenstorrent.
Scaling continues Data center chips are far less cost-sensitive than in consumer applications, so they tend to lead the industry in performance. A high-performance server amortizes chip development costs with the price of a system rather than through volume, which is essential for a mobile phone application processor, for example. So despite a never-ending stream of predictions about the end of Moore’s Law, the digital logic inside many of these devices will continue to use the latest process geometries for density reasons.
What’s different, though, is less performance-critical circuitry, as well as analog blocks, increasingly is being shunted off to separate chips, which are connected using high-speed interfaces.
“You now can partition by node,” said Matt Hogan, product director at Mentor, a Siemens Business. “So you can determine what is the correct technology for a particular portion of a design. That also allows you to scale some of the side effects.”
This approach was mentioned by Gordon Moore when he first published his now-famous observation in 1965.
“With the rapid evolution of process technology, it was typically cheaper to go with an off-the-shelf solution instead of developing custom chips,” said Tim Kogel, principal applications engineer at Synopsys. “By now, the free lunch of higher performance and lower power with every new process node is all but over. On the other hand, killer applications like AI, autonomous driving, AR/VR, etc., have an unquenchable demand for processing power and computational efficiency. Famous examples like Google’s TPU and Tesla’s FSD chips show the impressive ROI of tailoring the architecture to the specific characteristics of the target workload.”
Still, the value of Moore’s Law as originally written is waning, and that has both economic and technological implications. The economic benefits of planar scaling ended with the introduction of finFETs, when cost per transistor stopped decreasing from the previous node. Likewise, power/performance benefits have been decreasing since about 90nm. Y.J. Mii, senior vice president of R&D at TSMC, said that 3nm will bring performance improvements of just 10% to 15% for the same power, or 25% to 30% power reduction for the same speed.
This is hardly a dead end from a technology standpoint, however. Architectural improvements, including different packaging approaches and 3D layouts, can boost that performance by orders of magnitude. And scaling still helps to pack more density into those packages, even if the scaled-down transistors themselves aren’t running significantly faster.
“We have been bombarded by More-than-Moore topics for many years now,” said Tom Wong, director of marketing for design IP at Cadence. “But is it really area reduction, power reduction or transistor performance improvements (traditional PPA) that are driving these discussions, or is it silicon economics and the limitations of lithography/equipment that caused us to hit the brick wall? As it turns out, silicon economics and the limits of reticle size are the two things driving a disruption, which is necessitating designers to look at new ways of designing chips, and turning to new architectures.”
Both economics and reticle size limits are being addressed through different packaging schemes and a boost in reticle sizes, which allow for much bigger individual die. Doug Yu, vice president of R&D at TSMC, said that reticle sizes will increase by 1.7X with the foundry’s InFO (integrated fan-out) packaging approach. In addition, TSMC plans to introduce a 110 x 110 mm² reticle in Q1 of next year, which will increase reticle size by 2.5X.
All of this is necessary as the cost of putting everything onto a single die continues to rise. Modularity allows chipmakers to customize chips relatively quickly based upon a platform type of approach. CPU, GPU and FPGA chip designers figured this out more than five years ago, and have since started the march to disaggregated implementation by going to multi-die, and letting the interposer/packaging take care of the integration. This is one reason why die-to-die connectivity IP is taking center stage today, Wong said.
“CPUs, GPUs and FPGAs have all gone the route of chiplets because these companies design the chips (chiplets) themselves and need not rely on a commercial chiplet ecosystem. They can take advantage of what a chiplet-based design can offer,” Wong noted. “Multi-core designs, including CPUs, GPUs and FPGAs, can benefit from this architectural change/trend. SoC designs that can separate ‘core compute’ and high-speed I/Os also can benefit from this. AI acceleration SoCs and crypto SoCs are two examples. And datacenter switches and fabrics, such as 25.6Tb/s for hyperscale compute and cloud builders, also can benefit from this architectural change to chiplet-based design. These designs can be as complex as 20 billion+ transistors.”
So far this approach has been utilized by IDMs such as Intel, AMD and Marvell, each creating its own modular schemes and interconnects. So rather than building a chip and trying to pitch its benefits across a broad range of customers, they offer a menu of options using chiplets and, in Intel’s case, an assortment of connectivity options such as high-speed bridges.
Changes everywhere, some big, some tiny Putting all these changes into perspective is often difficult because the whole industry is in motion, although not necessarily at the same velocity or for the same reasons. So while processors and processes change, for example, memory lags well behind.
In addition, some technologies need to be completely rethought while others stay the same. This is particularly evident with GPUs, which have been the go-to solution for AI/ML training because they are cheap and scalable. But they are not the most energy-efficient approach.
“We’ve seen it with bandwidth, we’ve seen it with power,” said Kristof Beets, senior director of product management and technology marketing at Imagination Technologies “All of these different constraints come into play. From a GPU point of view it’s been a tricky evolution, because obviously GPUs are massive number crunchers, displays get ever bigger, and devices get ever smaller. So a lot of these problems keep hitting. There’s been a phase of brute force, which kind of depended on Moore’s Law. We were doubling the GPU, and for a while that was okay, because process technology kept up. But now that return is diminishing, so while we can put more logic down, we basically can’t turn it on anymore because it consumes too much power. So the brute force trick doesn’t work.”
Dynamic voltage and frequency scaling (DVFS) has helped a bit to ramp down the voltage, allowing for even bigger GPUs running at lower frequencies. Nevertheless, even that approach has limits because there are only so many GPU cores that can be used within a fixed power budget. “This gives us better FPS (frames per second) per watt, but even that is now starting to slow because leakage is going up again,” Beets said. “This is where, for GPUs, ray tracing has been interesting. It’s a way of switching away from brute force. They are very flexible. We’re seeing the same with AI and neural network processing. It’s exactly the same concept. This is where you’ve truly seen orders of magnitude solutions that are 10, 20 times better than the GPU by taking into account the data flow, the specific operations, so it’s quite interesting. It’s not quite as bad as the old days of fixed function processing. We’re not back there yet. But some of it is definitely starting to return with more dedicated processing types.”
There are many approaches to augmenting scaling performance. “There have been a few areas, such as application processors, GPUs, MCUs, DSPs, where we’ve had fairly general-purpose architectures exploiting Moore’s Law to do more and more,” said Roddy Urquhart, senior marketing director at Codasip. “But now there are a huge number of ideas around trying out novel architectures, novel structures, with a range of programmability. At the systolic array end, there are things that tend to be either hardwired processing elements, or they have processes that have firmware uploaded and left in a static condition for some time. At the other extreme are domain-specific processes, which are highly programmable. I see a return to innovation in the highly parallel, highly pipelined, array-type structures, which is a very good fit with neural networks of different sorts. At the other end, people are thinking more outside the box for moving out of the silos of MCU, GPU, DSP and application processors, and creating something that is more of a blended version of some of these things to meet particular needs.”
Micro-architectures Alongside of these broad architectural shifts are micro-architectural innovations. In many respects, this is a partitioning problem, where some compute functions are given priority over others within a larger system. That can have a big impact on both performance and computational efficiency.
“Taking advantage of the inherent parallelism, the application should be mapped to an optimal set of heterogenous processing elements,” said Synopsys’ Kogel. “Choosing for each function a processing core that provides the minimum required flexibility gives the highest possible computational efficiency. Also, the organization of the memory architecture has a very high impact on performance and power. Since external memory accesses are expensive, data should be kept in on-chip memories, close to where it is processed.”
This is easier said than done, however, and it requires multi-disciplinary and, increasingly, multi-dimensional planning. “It’s quite a challenge to manage the complexity and predict the dynamic effects of a highly parallel application running on heterogenous multi-processing platform with distributed memories,” Kogel said. “We propose the use of virtual prototyping to quantitatively analyze architecture tradeoffs early in the development process. This enables the collaboration of stakeholders from application and implementation teams, before committing to an implementation specification.”
New tradeoffs Going forward, how to proceed with power and performance tradeoffs depends on the market. Some markets are highly cost-sensitive, so they haven’t ramped into this problem yet. At the same time, others are less cost-sensitive and more latency-sensitive.
“People are increasingly impatient. You want to get stuff that you want as quickly as possible,” said Mike Mayberry, CTO of Intel, during a panel presentation at DARPA’s recent Electronics Resurgence Initiative (ERI) Summit. “But we’re also seeing balanced systems and more compute near the data, and that’s one of the trends we see continuing.”
Mayberry noted there is no hard stop on density scaling, but increasingly it will include the Z axis. “We’re also seeing novel beyond-CMOS devices that will enable heterogeneous architectures. A decade from now, you’ll see those on shelves.”
Intel, among others, is looking at ways to grow devices in addition to depositing and etching different materials. This has been talked about for years with such approaches as directed self-assembly. At some point that still may be economically viable, but the general consensus is probably not until after 3nm.
Alongside of all of this, photonics is beginning to gather some momentum as a way of moving large quantities of data in and around these increasingly dense structures with minimal heat. One of the more novel approaches involves using light for processing, which LightMatter CEO Nick Harris said is free from effects like time-dependent dielectric breakdown because it doesn’t rely on transistors. What’s particularly unique about this approach is that light can be partitioned into different wavelengths, allowing different colors to be given different prioritization.
“With 100GHz wavelengths, which is really small spacing, we can fit 1,000 colors,” Harris said. The downside is lasers don’t last forever, so there needs to be enough redundancy to allow these systems to last throughout their expected lifetimes.
For more traditional computing, the number of process node options is increasing, as well. Foundries are offering in-between nodes, which improve performance or power without a complete redesign. For example, TSMC uncorked its N4 process, which will enter risk production at the end of next year. C.C. Wei, CEO of TSMC, said in a presentation that IP used in both N5 (5nm) and N4 will be compatible, which allows companies to improve density and lower power with minimal redesign.
Still, the number of options is dizzying. In addition to different node numbers, there also are different process options for low power and for high performance. On top of that, different substrate materials are beginning to gain traction, including silicon carbide and gallium nitride for power transistors, and silicon-on-insulator for lower-cost, low-power applications.
All of that has a big impact on design rules, which are used to prevent failures. “If you’re designing a chiplet, you don’t know how it’s going to be used or placed,” said Mentor’s Hogan. “You don’t know if it’s going to be next to an MCU, so you have to figure out how to do that in a thoughtful way. You need to protect it from electromagnetic effects and other potential issues.”
And because chips are expected to function properly for longer periods of time — in the case of automotive, it may be as long as 18 years for leading-node logic — all of this needs to be done in the context of aging. This can get extremely complicated, particularly in multi-chip packages.
“You need to look at things like threshold shifts with different stimuli and scenarios,” said Vic Kulkarni, vice president of marketing and chief strategist for the semiconductor business unit at Ansys. “You can do a precise analysis of registers, but if the Vdd is not going down and the Vt is not going down, there isn’t much margin left. You also need to think about things like electrical overstress. The fabs are not willing to take that on.”
Tradeoffs range from power, performance, and cost, to quality of service.
“We used to always have lossless compression,” said Imagination’s Beets. “And about one or two years ago, we introduced lossy, as well, so we could trade off on quality. In GPUs, we’re starting to see across the board a tradeoff of quality versus cost, and the lossy compression allows the quality to be decreased, which also saves on bandwidth and power. In GPU processing, we’re starting to see the same thing, which is variable rate shading. This is basically when you look at a video, you’d say all you really care about is the face, and you want that in full detail, so the background doesn’t matter. Games essentially do the same thing. For example, in a racing game the car is very sharp and has a lot of detail, but the rest has a motion blur on it.”
There also are tradeoffs in precision. Lower precision can greatly speed up processing, and sparser algorithms can be written to be less precise, whether that’s 16-bit precision or even 1-bit precision. But that precision also can be controlled by the hardware and firmware, and it can have a big impact on overall system performance where some functions are made more accurate than others.
Conclusion For the first 40 years or so of Moore’s Law, power, performance and area improvements were sufficient for most applications, and the growth in data generally was manageable through classical scaling. After 90nm, classical scaling started showing signs of stress. So the writing has been on the wall for some time, but it has not gone unheeded.
What’s surprising, though, is just how many avenues are still available for massive improvements in performance, lower power and potentially cost savings. Engineering teams are innovating in new and interesting ways. Decades of research into what seemed like obscure topics or tangents at the time are now paying off, and there is plenty more in the pipeline.
‘Customer research? We just made a car we thought was awesome and looked super-weird.’
This article comes to us courtesy of EVANNEX, which makes and sells aftermarket Tesla accessories. The opinions expressed therein are not necessarily our own at InsideEVs, nor have we been paid by EVANNEX to publish these articles. We find the company’s perspective as an aftermarket supplier of Tesla accessories interesting and are willing to share its content free of charge. Enjoy!
Posted on EVANNEX on September 01, 2020 by Iqtidar Ali
“I just wanted to make a futuristic battle tank, something that looked like it came out of Bladerunner or Aliens or something like that,” Elon Musk explained in a recent Automotive News Daily Drive podcast.
Above: Elon Musk looks back at his controversial truck (Source: Tesla via XAuto)
“Customer research? We just made a car we thought was awesome and looked super-weird,” explained Musk. “The body panels are bulletproof to a handgun so it’s probably helpful in the apocalypse,” he added. “Let me tell you, the truck you want in the apocalypse is the Cybertruck. We wish to be the leader in apocalypse technology.”
As a matter of fact, according to Tesla, the Cybertruck’s 30x cold-rolled stainless steel body is bulletproof against a 9mm handgun. Elon Musk also demonstrated this in his presentation at the Cybertruck launch event last year. This “body armor” along with the infamous armored glass makes Cybertruck a perfect fit for typical apocalyptic threats.
Musk even teased this futuristic battle tank theme when hinting about a “Cybertruck option package” recently on Twitter. Okay… but what would this so-called Cybertruck option package actually look like in real life?https://www.youtube.com/embed/wrJoT6jQ6Jk
Above: Some creative armored Cybertruck concepts for both civilian and military use (YouTube: Jan Peisert)
It turns out a daring graphic designer, Jan Peisert, has rendered some really cool armored Cybertrucks with both civilian and military applications in mind. He created four unique variants of an armored Cybertruck: Civil (Plaid Apocalypse), Transport (Next Humvee), Combat (Tank), and Reconnaissance (Quiet Scout). Check out his wild creations, including annotated “blueprints” for each, in his video above.
One of Peisert’s armored Cybertruck concepts showcases a menacing (albeit civilian) option package — complete with additional bumpers on the side, an extended front bumper and further reinforced armored glass on the windows and roof.
Meanwhile, an especially smart feature on one of Peisert’s military concept vehicles includes a foldable solar panel on the roof. This could prove handy at providing energy while hiding out for long periods of time — especially in the desert with lots of sunlight available for free charging.
GALLERY
Apocalypse or not, the Cybertruck is a great fit for the needs of the military. We’re not really sure whether governments around the world are interested in replacing their gasoline-powered military vehicles. But if they were, something like this just might work.
Photo by BONNINSTUDIO / StocksyOur editors have independently chosen the products listed on this page. If you purchase something mentioned in this article, we may earn a small commission.August 31, 2020 — 11:36 AMShare on:
Night showerers, gather. There’s one notorious downside to an evening rinse that many—especially if you have longer hair that takes a while to dry—often complain about: Going to bed with wet hair. It’s a habit born of necessity: Some of us simply cannot wait out the time between our nightly wash and bedtime and thus have to sleep with damp strands. (This is especially true if you air dry and loathe putting a blow dryer to your hair.) And yet, so many still feel somewhat guilty about this hair care habit.
Just mentioning that you frequently go to bed with wet hair will trigger aghast faces from most experts: It’s something that is widely considered a no-go. But, c’mon, is it really that bad? And even if it’s not ideal for strands, is there any way to make it better for the nights there’s really no other option? Or are you—gasp—going to be forced into a life of morning showers for good?
Here, we answer your burning questions.
Is it bad to sleep on wet hair? What the experts say.
OK, there is some truth that sleeping with wet hair isn’t the best way to treat hair. The main reason is that the structural integrity of hair weakens when wet, as cuticles naturally lift up when damp, making the hair more elastic, vulnerable, and prone to breakage. Along with that, there are also scalp concerns associated with sleeping with wet hair—as well as simple aesthetic issues.
“Simply put, hair is at its most vulnerable when wet. Sleeping with wet hair can lead to a host of problems for the scalp: unwanted bacteria, fungal infections, skin irritation, itchiness, dryness, redness, and dandruff,” says hairstylist Miko Branch, co-founder of hair care brand Miss Jessie’s Original. “Also, it can damage the hair cuticle, flatten strands, create an unpleasant hair odor (dampness mixed with natural sweat) and leave you with a matted mess of hair.”
Essentially, the most concerning part about sleeping with your hair wet is that it leaves your hair open to damage, tangling, and splits. So if you are someone who perpetually wakes up to knotted, frizzy, and brittle strands, you may want to quit the night shower. And, too, if you are also someone who suffers from scalp concerns like irritation, flakes, and inflammation, you may also need to reevaluate your habit, as it may be the root cause you hadn’t considered yet.
So sounds, ahem, not great. However, most stylists will also agree that there’s certainly some nuance here. “I think something like this is case by case,” says hairstylist Marcus Frances, an ambassador for hair care brand Better Natured. “Yes, when the hair is damp it usually is more fragile so the friction against your pillow can, not always, further weaken the hair causing split ends or breakage. But this tends to be a bigger concern for those who already have really damaged hair. If that’s not you, you’ll probably find you don’t run into these issues.”
Basically: if you find that it’s not messing with your scalp, style, or strands, you can continue as normal, just with a few of these caveats. ADVERTISEMENThttps://3ecc946805ebb01b5b3e53df6e72bff1.safeframe.googlesyndication.com/safeframe/1-0-37/html/container.html
How to safely sleep with wet hair.
So you’ve decided it’s not always realistic to sleep on perfectly dry hair; well, there are ways to make sure you are caring for your hair while it’s more fragile. Here, expert care tips to make sure your sleeping habits aren’t messing with your strands:
1. Wash less.
One of the easiest ways to limit the amount you are sleeping on wet hair is to wet it less. Now, how much you shampoo your hair is a personal decision influenced by your scalp, hair type, and lifestyle, and for those with textured or curly hair, Branch suggests that you really should be limiting the amount that you get your hair wet. “Textured hair, in particular, is even more fragile as it tends to be dry. Therefore, curly hair should be washed less often–once or twice a week is perfect–with gentle cleansers and moisturizing conditioners,” she says.
2. Add as much buffer time between your rinse and sleep as possible.
Be honest with yourself: Is the fact that you’re going to bed with soaking hair due to the fact that you literally have no other time to shower than right before bed, or is it true that you could have rinsed earlier and just put it off? If the former: Life happens and so do busy schedules; you’ll receive no judgment here. If the latter: Consider inching up your shower into earlier in the evening.
This will give your hair time to air dry, so even if your strands aren’t perfectly free of moisture, they’re better than sopping wet. “I would love to mention that sleeping with ‘wet’ hair isn’t great, but ‘damp’ hair, where there is some air and dryness throughout the hair, is fine,” says Frances.
Branch agrees: “Always take a few minutes and try to let the hair dry before going to sleep—either air dry (the best dry), use a microfiber towel to blot excess water, or use a diffuser on a blow dryer set to low to get out some of the moisture.”
3. Sleep with a silk pillow, scarf, or cap.
Silk sleeping accessories aren’t just luxe-looking (although, they’re definitely that too); they can also help keep your strands strong, hydrated, and smooth: “Sleep with a silk or satin pillowcase, headscarf, or cap, which allows hair to slide as you toss and turn while sleeping. Unlike cotton, silk and satin prevents friction (which leads to hair pulling, tugging, stretching, breaking, and tangling), and these smooth fabrics help retain the hair’s natural oils,” says Branch.
4. Apply a leave-in to protect it from physical damage.
One of the main duties of a leave-in is to protect hair from physical damage. Essentially, they coat the strand with a protective layer of nutrients, oils, and emollients that keep hair from snagging and tangling.
5. Embrace the bedhead.
One concern is that sleeping on wet hair just means you’re waking up to hair that needs to be restyled with hot tools. Not true: “For someone who likes to keep their natural texture, sleeping with damp hair can actually be great, style-wise. There’s something about when you sleep on your hair that creates a more natural version to your texture that is hard to replicate with tools or products,” says Frances.
This may just take some experimenting to figure out what products you need to apply and how best to “style it” as you sleep. For example, for those with very loose waves who are looking to amp up texture, using braids may be more beneficial; those with curls may employ the ‘plopping method‘ with a silk scarf or water-wicking T-shirt to really get the hair to spring.
The takeaway.
Going to bed with wet hair may not be the best choice for some of us (if you find that you have damage or scalp issues), so in those cases we do recommend figuring out a new wash schedule so your hair is better cared for. However, if you haven’t noticed a problem yet, you’re probably fine: Just add a few extra hair care steps before you sleep and you’ll be good to go.
Alexandra Englermbg Beauty and Lifestyle Senior EditorAlexandra Engler is the Beauty and Lifestyle Senior Editor at mindbodygreen. She received her journalism degree from Marquette University, graduating first in the department.
Given the unprecedented challenges of recent months, it’s perhaps unsurprising that many of us are experiencing sleep deprivation.
In a recent survey conducted in the United Kingdom, around 75% of respondents said that unease around the COVID-19 outbreak has caused sleep disruption, while 77% reported that lack of sleep has interfered with their day-to-day functioning.
Lack of sleep can lead to several mental and physical health problems, including depression, diabetes, cardiovascular disease, and obesity, highlighting the importance of getting a sufficient amount of shut-eye.
With this in mind, we decided to dig a little deeper into the world of sleep this month. We explored the science behind slumber and provided you with further information and resources to help you get a good night’s sleep.
“Definitely, people are reporting more dream recall, more vivid dreams, more bizarre dreams, and more anxious dreams since March,” Deirdre Barrett, Ph.D., an assistant professor of psychology in the Department of Psychiatry at Harvard Medical School in Boston, MA, told us.
We aimed to dispel some of the widespread myths surrounding sleep with the first of our Medical Myths series. Does your brain really shut down during sleep? This article helps clear things up.West Nile virus: Exclusive analysis on climate and health
Medical News Today analyzes how changes in temperature and precipitation over time have affected the epidemiology of West Nile virus.
To find more information and resources on sleep, visit our dedicated hub.
Continuing our coverage of racial disparities, we recently published an article on how to be an ally. This important piece highlights the need for all of us to be active in the fight against racism.
“The burden of fighting against racial inequality must not fall on Black people exclusively. The recognition of this fact is necessary when fighting to keep the movement alive in demanding for tactical change.”
Other content that has piqued your interest this August includes our coverage of research suggesting that an existing drug called Ebselen — previously used to treat bipolar disorder and hearing loss — may help combat COVID-19. You were also interested in our article on a study that suggests COVID-19 symptoms may appear in a certain order.
For those of you who wish to take a break from COVID-19-related news, the latest in our Recovery Room series looks at what’s been happening elsewhere in the world of medical research.
Is there a health topic you’d like to read more about? Let us know by emailing us at editors@medicalnewstoday.com. You can also reach out to us on Facebook and Twitter.
I’ll return next month with more on what you’ve been reading.
Who will guide our future: Machines or human minds?
4 min read. Updated: 26 Aug 2020, 08:15 PM ISTBiju Dominic
GPT-3 displays impressive artificial general intelligence but is just another software tool at our disposal
OpenAI’s new software, called GPT-3, is by far the most powerful “language model” ever created. With small prompts, it can draft letters eerily close to what a human would produce. It can respond to emails. It can translate texts into many languages.
This language model is an AI system that has been trained on large corpus of text. In this case, “large” is something of an understatement. Reportedly, the entirety of the English Wikipedia, spanning some 6 million articles, makes up just 0.6% of GPT-3’s training data. There is a point of view that GPT-3 is an important step toward artificial general intelligence, the kind that would allow a machine to reason broadly in a manner similar to humans without having to train for every specific task it encounters.
But, a few days ago, an article by Gary Marcus and Ernest Davis in MIT Technology Review, ‘GPT-3, Bloviator: OpenAI’s language generator has no idea what it’s talking about’, poured cold water on the huge hype around GPT-3’s launch. According to the authors, it can be used to produce entertaining surrealist fiction; other commercial applications may emerge as well. But accuracy is not its strong point. Although its output is grammatical, and even impressively idiomatic, its comprehension of the real world is often seriously off.
To understand why this could have happened, it helps to think about what systems like GPT-3 do. They don’t learn about the world, they learn about text and how people use words in relation to other words. With enough text and processing capacity, the software learns probabilistic connections between words. What it does is akin to an elaborate cut-and-paste act that uses variations on text it has seen, rather than understanding the real meaning of that material.
A software that writes without understanding what it’s writing raises the prospect of frightening misuse. The creators of GPT-3 themselves have cited a litany of dangers, including “misinformation, spam, phishing, abuse of legal and governmental processes, fraudulent academic essay writing and social engineering pretexting”. Because it was trained on text found online, it’s likely that GPT-3 mirrors many biases found in society.
This is not the first time that an emergent technology has seemed to pose an existential threat. It was feared that nuclear energy will contaminate the world. DNA engineering was expected to unleash biological warfare. These prophesies of doom did not materialize. It is important to take care of the possible negative consequences of a new technology. But that should not put shackles on its progress.
The creators of GPT-3 are already taking steps in the right direction. They prohibit GPT-3 from impersonating humans; that is, all text produced by it must disclose that it was written by a bot. OpenAI has also invited external researchers to study the system’s biases, in the hope of mitigating them. Will all this mitigate human fears of this new technology?
One of the best perspectives on this conflict between brain and machine comes from an article in Aeon, ‘At the limits of thought’’, by David C Krakauer, president and William H Miller Professor of Complex Systems at the Santa Fe Institute in New Mexico. Francis Bacon was one of the first to propose that human perception and reason could be augmented by tools. Isaac Newton adopted Bacon’s empirical philosophy and spent a career developing tools: physical lenses and telescopes, as well as mental aids and mathematical descriptions, all of which accelerated scientific discovery. A growing dependence on instruments led to disconcerting divergence: between what the human mind could discern of the world’s underlying mechanisms, and what various tools were capable of measuring and modelling.
Early tools like rulers and compasses helped humans do what once took a lot of effort with greater ease and precision. As tools became more advanced, they started doing things humans could never do. A telescope could see far farther than what a human eye could. But the telescope still functioned like an enhanced human eye. Then came a stage where tools were performing functions very differently from how humans would. With the radio telescope, machines were seeing things rather differently from how the human eye sees things.
In this age of “big data”, the divergence between what the human senses can do and what new tools can do has become even more startling. These new sophisticated tools are capable of analysing “high-dimensional” data-sets, and the predictions they provide often defy the best human ability to interpret them. It has become nearly impossible for humans to reconstruct how these tools function. This has not been music to the ears of the stubbornly anthropocentric who insist that our tools yield to our intelligence. This attitude could impede the advancement of science.
Much like the compass and the telescope, GPT-3 is yet another tool that humans have at their disposal. Without tools, humans would still be spending a lot of time trying to draw perfect circles and straight lines. Tools have helped us focus our attention beyond the mundane. Similarly, GPT-3 too could help us get out of many mundane tasks of writing that we have been involved in for centuries. It could help focus human attention and intelligence on more advanced things, such as seeing galaxies that lie beyond our line of sight. No doubt, GPT-3 will also make the few personal handwritten notes you write even more precious.
Biju Dominic is the chief executive officer of Final Mile Consulting, a behaviour architecture firm.
If you’re a fan of the theming used by Mozilla for its Firefox range of products, you’ll like Firefox 81 when it comes out in the next several weeks. With Firefox 81, users will be able to choose the Alpenglow theme which uses purples and oranges predominantly.
The new theme will be accessible to users from the about: addons, about:welcome, and the Customise UI menus alongside the Automatic, Light, and Dark themes that have been available to pick from for a long time already. The new theme doesn’t offer any practical benefits but if you’re a fan of the aesthetics in the new Firefox mobile browser on Android, you’ll probably be a fan of this theme too.
In its Firefox Nightly News post, Mozilla also revealed that Nightly builds now ship with easier access to search engine one-offs and @aliases. A bug report opened three months ago suggested that one-off searches should be easier to discover.
It’s not clear when the new search engine update will finally make it to the stable Firefox branch but users should expect the new Alpenglow theme in Firefox 81 which comes out in September.
What makes a pair of fashionable shoes and a swimsuit unmissable in the suitcase prepared for a weekend to the beach? And why not within the just-bought hiking boots a one-click booking into a camping in the Dolomites, because you love adventures? The system that invents those suggestions might be the one that leverages the power of networks, metaphors of our collective life, with all of its complexity and its entangled dependencies.
In particular, two types of networks, the network of data and the network of artificial neurons when combined together open the way to a variety of interesting applications. Typical examples of data networks include social networks and the knowledge graphs, while, on the other hand, a new family of machine learning tasks based on neural networks has grown in the last few years. This lineage of deep learning techniques lay under the umbrella of graph neural networks (GNN) and they can reveal insights hidden in the graph data for classification, recommendation, question answering and for predicting new relations among entities. Do you want to know more about them?
When we talk of machine learning tasks, we refer to a set of algorithms that finds correlation between input and output. The input is basically a list of numbers also known as vectorized features:
Symbol
Vector representation
hiking
0.12, 0.25, 0.66, 0.45
mountain
0.16, 0.29, 0.62, 0.40
seaside
0.02, 0.70, 0.39, 0.60
The vector representation of the nodes in the knowledge graph should preserve, to the maximum extent, the information carried by the single node within its own attributes compressed in a low dimensional space. In other words, the embeddings (the name of the vectorized representation) should identify the related symbol with a vector, and such vectors should be as small as possible. The objective of this article is about to find a proper way to generate good embeddings out of knowledge graphs.
For being useful in downstream machine learning tasks, embeddings should not just identify the related symbol but also they should have an important property. Symbols that are similar to each other – for whatever criteria we define for ‘similarity’ – should be associated with embeddings that are also similar, according to the favorite distance functions. In the above example, Hiking embeddings are more closely related to Mountain rather than Seaside. Embeddings are very familiar for those practiced in natural language processing, and they are based on the principle “a word is characterized by the company it keeps (R. Firth)”, and the skip-gram technique is employed for predicting what is the most likely word surrounded by a given set of predecessors and successors. Applied to a huge corpora, the trained skip-gram (or its complementary cbow) network will contain the embeddings that fulfill the similarity property.
While the words in a text are strictly in sequential order (with one predecessor and one successor), in a graph a node might hold a multitude of relations, and as if that is not enough, those relations might be different one to another. Representation learning is flourishing and new approaches are invented at an increasing rate.
Tecniques for generating embeddings with neural networks
Hereafter, I will present just two techniques for generating embeddings in graphs. For the sake of statistics, I implemented Deepwalk and Graph convolutional networks (GCN) in Scala with ND4J for matrices, and Deeplearning4J as a neural network framework.
Deepwalk algorithm
The Deepwalk (and its successor Node2Vec) is an unsupervised algorithm, one of the first in the realm of representation learning for graphs, and it is as simple in its design as it is effective on capturing topological and content information. In principle it is equivalent to the already mentioned skip-gram, but how can the graph structure match the streaming sequence of words in a text? Starting from any node of choice, the algorithm visits its neighbors and the entire network in a controlled random way. The random walk is balanced among two different approaches that emphasize differences in closely related nodes in one case, and the differences among distant clusters in the other. The first approach is the Breadth First Search (BFS) which selects the next node to visit among the siblings of the current node, in the respect of the previous node. The second approach is the Deep First Search (DFS) that selects the new node among the connected nodes with the current one. The first persists with all neighbors of the current node, while the second tends to explore the network in depth.
Clusterization on Karate dataset with Deepwalk
What are the Graph Convolutional Networks?
The graph convolutional networks, as the name might recall, share some commonalities with the convolutional neural network algorithm, the one that led the way to giant leaps in visual recognition. If a graph with nodes and edges is transposed in a two dimensional adjacent matrix, nothing can prevent us from running a sliding window function that compresses a grid of pixels and extracts features like CNNs do. The affinity with CNN ends here, because when we elaborate images we are more interested in complex visual features rather than single pixels, while in knowledge graphs we want to convolute in a single node its neighbours and recursively the information of the entire network.
The Weisfeiler-Lehman Test
The principle underlying GCNs lay its fundations on a method described several decades ago in the Weisfeiler-Lehman test. The test determines whether two arbitrary graphs are isomorphic, i.e. they have exactly the same structure. According to the algorithm, all nodes are initialized with the same value, let’s put number 1 for all. Then, to that node is assigned that value plus the value of its neighbors, and this step is iterated. As you might think, in the first round the node already includes the information of first degree neighbors, but at the second iteration, the node will get a distilled notion of the second line of nodes, and so on as the iterations proceed. The test will confirm the isomorphism whether, after an arbitrary number of iterations, the partition of nodes by their current value does not change. Even though the final check is irrelevant for GCNs, the method brings the way to iteratively convolve information among the nodes.
The Spectral Propagation Rule
The GCN method is described in Kipf & Welling (ICLR 2017) and lies in the messaging passing methods family, whereas with “message” we intend solely the content of a single node and “passing” is the convolution which percolates throughout the network. While in the Weisfeiler-Lehman test the way to pass information is just a simple sum of values, in GCNs the convolution relies on the spectral propagation rule. What is this propagation rule? Let’s assume we know the graph structure (nodes and relations) and the content of all nodes (features). The propagation rule is applied with a linear matrix multiplication, but for not incurring in vanishing or exploding gradients in the downstream tasks, the features are normalized and a self-loop in the adjacency matrix is added.
Spectral Propagation Rule in Scala and ND4J
I created some experiments with the small karate dataset, a fake set of node features (just a diagonal matrix) and a random set of weights. I repeated 4 experiments in sequence (no cherry-picking) in the image below where the color of the nodes indicates their similarity after running 2 iterations of the spectral algorithm.
2 Iterations with Spectral Propagation Rule. Each figure is a separated run
The results are clearly amazing! The two clusters are yet unrefined but as you can see the figure (d) is almost exactly what we obtained with Deepwalk! Those embeddings are elaborated with just random weights and 2 recursive iterations. Why not apply some learning mechanism for refining the clusterization with few examples?
Semi-supervised Learning with GCNs
I started this post on how your e-commerce could recommend new items according to your customers’ holiday preferences and I’ll run some experiments with a more pertinent dataset. If you are not familiar with ConceptNet, it is a huge graph database of general facts with 34 millions nodes, 34 types of different relations (I used ConceptNet for other ideas, check them out!) that I converted entirely in a OWL database. I extracted approximately 3 thousands of nodes about our topics of interest, the mountain and the seaside. Then I created a 2-layered neural network with the spectral propagation rule. I fed it with the adjacency matrix, the word-embeddings of the node names as input features and some labelled nodes, in total 4, 2 nodes classified as “seaside” category, and 2 nodes classified as “mountain” category. The 4 labelled nodes with 2 categories is all I need for classifying all the rest of the 3 thousands labels. That’s a ratio of 4/3000 labelled entries in the respect of the entire dataset, isn’t interesting? That’s why the name semi-supervised learning.
ConceptNet snapshot. Red nodes are labelled “mountain”, the blue are “seaside”, the green none of them.
This method of classification is really fast but has some drawbacks. The spectral propagation rule takes into account the adjacency matrix which is the whole network in a two dimensional vector. For a relatively small dataset that’s not an issue, but when it comes with real big data this method is actually unfeasible. The FastGCN comes into the rescue and scales to big sized graph DBs.
Giancarlo Frison is Technology Strategist at SAP Customer Experience Labs
Is this Cold Fusion deja vu all over again? Maybe. Or maybe not.
Today, batteries can run out in days. Imagine having batteries that can last lifetimes. (source)
On my news aggregator yesterday was a story on newatlas.com titled, “Nano-diamond self-charging batteries could disrupt energy as we know it.” What the hell? That pegged out my weird-s**t-o-meter, so I had to read it.
First, here’s the backstory. It turns out that in 2016, back when [political rant deleted for space], a group of scientists at the University of Bristol took some radioactive waste graphite, squeezed it into teensy-weensy diamonds…and those diamonds generated a small amount of energy all by themselves, though not enough to power a cell phone. You see, in many reactors, graphite is used as a moderator to control the heat flow, and when the reactor is refueled or decommissioned, all the graphite removed is rich in carbon-14 and is highly radioactive, and at that time the United Kingdom had 95,000 tons of it sitting around pumping out zoomies (which is how we sometimes referred to radiation in the Navy), its half-life of 5730 years providing motivation for hundreds of generations of protesters.
According to a 2017 article by the Snopes fact-checking service, the concept of transforming radioactive waste graphite into electricity-emitting diamonds has been around since at least 1973, and that it might be possible to safely encase the nano-diamond battery inside another diamond and and use the resultant “betavoltaic” diamond to generate electricity.
So a company in California named NDB (for “Nano-Diamond Battery”, strangely enough) appears to have done just that. They claimed to have improved the process to the point where the radioactive nano-diamonds can generate enough electricity to be not just useful, but commercially viable and scalable. Here’s how the newer article explained the process:
This graphite is rich in the carbon-14 radioisotope, which undergoes beta decay into nitrogen, releasing an anti-neutrino and a beta decay electron in the process. NDB takes this graphite, purifies it and uses it to create tiny carbon-14 diamonds. The diamond structure acts as a semiconductor and heat sink, collecting the charge and transporting it out. Completely encasing the radioactive carbon-14 diamond is a layer of cheap, non-radioactive, lab-created carbon-12 diamond, which contains the energetic particles, prevents radiation leaks and acts as a super-hard protective and tamper-proof layer.
Most of us would think that manufacturing a radioactive diamond and encasing it inside another manufactured diamond sounds outrageously expensive. Answers on Quora and Reddit indicate about $2300 per carat (’cause the internet never lies, right?), and one can’t help but wonder how much more it costs with radiation hazard mitigation measures. In an interview, the Chief Strategy Officer at NDB said that their manufacturing process is somewhat more expensive than for lithium-ion batteries, but the latter need to be charged, whereas NDB’s are not only self-charging, but:
“Think of it in an iPhone. With the same size battery, it would charge your battery from zero to full, five times an hour. Imagine that. Imagine a world where you wouldn’t have to charge your battery at all for the day. Now imagine for the week, for the month… How about for decades? That’s what we’re able to do with this technology.”
Even after one year, today’s iPhones can lose over one-third of their capacity (source)
He claims the technology is scalable enough to power electric cars where the batteries may have a useful life of up to 90 years. Let that sink in for a moment: a self-charging battery that can power your car for 90 years, for not much more than what current electric-vehicle batteries cost today. The company claims it can even be used to power aircraft.
Damn.
I hate being a cynic. Read most of my articles — hope and optimism drips off them like honey poured over…well, let’s not go there. But even an eternal Pollyanna like me must acknowledge the fact that if it sounds too good to be true, it probably is. After all, I’m old enough to remember the cold fusion fiasco of 1989 where two scientists named Pons and Fleischmann had claimed to produce fusion — that holy grail of energy production — at room temperature. The hype and hope were insane, and energy would be cheap and plentiful for all…until it all went up in smoke like so much phlogiston, and the two scientists’ names became synonymous with the danger of not adhering to strict standards of scientific rigor. The collective dreams of geekdom were dashed upon the baryonic rocks of the scientific method. Yes, even today there’s highly-qualified scientists striving to make cold fusion work, but more and more it’s looking like a high-tech version of a perpetual motion machine.
As far as NDB goes, it seems the jury is still out. Just because a scientific concept seems possible, that doesn’t mean the engineering on a mass-production scale is feasible, much less commercially viable. According to Germany-based finanzen.net:
NDB…today announced completion of two successful Proofs of Concept tests of the NDB battery at Lawrence Livermore National Laboratory and the Cavendish Laboratory at Cambridge University. NDB’s battery achieved a breakthrough 40% charge, a significant improvement over commercial diamonds, which have only 15% charge collection efficiency. NDB also announced its first two beta customers, including a leader in nuclear fuel cycle products and services and a leading global aerospace, defense and security manufacturing company. Development of the first NDB commercial prototype battery is currently underway and will be available later this year.
So it’s definitely a maybe. We may have seen this movie before, and if so, it doesn’t end well. But if this technology pans out, we could have safe, relatively-green, radioactive-waste-mitigating, and self-recharging batteries that we can pass down to our kids and grandkids, and for not much more than we’re paying for lithium-ion batteries today.