Tech Firms Train Voice Assistants to Understand Atypical Speech
Voice assistants like Alexa and Siri often can’t understand people with dysarthria or a stutter; their creators say that may change
Amazon recently announced a tie-up with Voiceitt, a startup that lets people with speech impairments train an algorithm to recognize their vocal patterns.PHOTO: ELAINE THOMPSON/ASSOCIATED PRESS
By Katie DeightonFeb. 24, 2021 12:00 pm ET
PRINT
TEXT
Dagmar Munn and her husband purchased a smart speaker from Amazon.com Inc. for their home in Green Valley, Ariz. in 2017, seven years after Ms. Munn was diagnosed with amyotrophic lateral sclerosis, the motor neuron disease more commonly referred to as ALS.
At first the speaker’s voice assistant, Alexa, could understand what Ms. Munn was saying. But as her condition worsened and her speech grew slower and more slurred, she found herself unable to communicate with the voice technology.
“I’m not fast enough for it,” Ms. Munn said. “If I want to say something like ‘Alexa, tell me the news,’ it will shut down before I finish asking.”
Ms. Munn can’t interact with voice assistants such as Alexa because the technology hasn’t been trained to understand people with dysarthria, a speech disorder caused by weakening speech muscles. People with a stutter or nonstandard speech caused by hearing loss or mouth cancer can also struggle to be understood by voice assistants.
NEWSLETTER SIGN-UP
The Experience Report
Get weekly insights into the ways companies optimize data, technology and design to drive success with their customers and employees.PREVIEWSUBSCRIBE
Approximately 7.5 million people in the U.S. have trouble using their voices, according to the National Institute on Deafness and Other Communication Disorders. Julie Cattiau, a product manager in Google’s artificial intelligence team, said that group is at risk of being left behind by voice-recognition technology.
Google is one of a number of technology companies now trying to train voice assistants to understand everyone.
Some made investments into voice accessibility after realizing that people with dysarthria—often a side effect of conditions including cerebral palsy, Parkinson’s disease or a brain tumor—may be the group that stands to benefit most from voice-recognition technology.
“For someone who has cerebral palsy and is in a wheelchair, being able to control their environment with their voice could be super useful to them,” said Ms. Cattiau. Google is collecting atypical speech data as part of an initiative to train its voice-recognition tools.
Training voice assistants to respond to people with speech disabilities could improve the experience of voice-recognition tools for a growing group of potential users: Seniors, who are more prone to degenerative diseases, said Anne Toth, Amazon’s director of Alexa Trust, a division that oversees the voice assistant’s privacy and security policies and features, as well as its accessibility efforts.
Amazon in December announced an Alexa integration with Voiceitt, an Israeli startup backed by Amazon’s Alexa Fund that lets people with speech impairments train an algorithm to recognize their own unique vocal patterns. Slated to go live in the coming months, the integration will allow people with atypical speech to operate Alexa devices by speaking into the Voiceitt application.
Apple Inc. said its Hold to Talk feature, introduced on hand-held devices in 2015, already lets users control how long they want the voice assistant Siri to listen for, preventing the assistant from interrupting users that have a stutter before they have finished speaking.
The company is now researching how to automatically detect if someone speaks with a stutter, and has built a bank of 28,000 audio clips from podcasts featuring stuttering to help do so, according to a research paper due to be published by Apple employees this week that was seen by The Wall Street Journal.
The data aims to help improve voice-recognition systems for people with atypical speech patterns, an Apple spokesman said. He declined to comment on how Apple may use findings from the data in detail.
Google’s Project Euphonia initiative is testing a prototype app that lets people with atypical speech communicate with Google Assistant and smart Google Home products by training software to understand their unique speech patterns. But it’s also compiling an audio bank of atypical speech that volunteers—including Ms. Munn—contribute to.
Muratcan Cicek, a Google summer intern who was born with cerebral palsy, tests a Project Euphonia prototype application. The technology aims to help Google’s voice assistant understand people with atypical speech.PHOTO: GOOGLE
Google hopes that these snippets will help train its artificial intelligence in the full spectrum of speech and bring its voice assistant closer to full accessibility, but it isn’t an easy task. Voice assistants can recognize most standard speech because users’ vocal harmonies and patterns are similar, despite their different accents. Atypical speech patterns are much more varied, which makes them much harder for an artificial intelligence to understand, said Google’s Ms. Cattiau.
“As of today, we don’t even know if it’s possible,” she said.
Critics say technology companies have been too slow in addressing the issue of accessibility in voice assistants, which first became available around 10 years ago.
Glenda Watson Hyatt, an accessibility advocate and motivational speaker who has cerebral palsy, said some disability surveys don’t report on the prevalence of speech disabilities, so if technology companies “relied on such data to help determine market size and needs, it is obvious why they overlooked or excluded us.”
People working in voice accessibility say the technology only relatively recently became sophisticated enough to attempt handling the complexities of nonstandard speech. They also said many technology firms weren’t placing so much emphasis on inclusive design when the first voice assistants were being built.
Contributing to projects such as Project Euphonia can also be difficult for people with atypical speech. Ms. Munn says she sometimes finds speaking physically exhausting, but is happy to contribute if it helps teach a voice assistant to understand her.
New Contextual Calibration Method Boosts GPT-3 Accuracy Up to 30%
A research team from UC Berkeley, University of Maryland and UC Irvine identifies pitfalls that cause instability in the GPT-3 language model and proposes a contextual calibration procedure that improves accuracy by up to 30 percent.
Today’s large language models have greatly improved their task-agnostic, few-shot performance, with top models like GPT-3 competitive with state-of-the-art finetuning approaches when provided only a few examples in a natural language prompt. This few-shot, “in-context” learning approach is gaining traction in large part due to its ability to learn without parameter updates. Compared to traditional finetuning methods, few-shot learning enables practitioners to more quickly prototype NLP models, allows non-technical users to create NLP systems, and efficiently reuses models to reduce system memory and complexity.
GPT-3’s accuracy however can be highly unstable across different prompts (training examples, permutation, format). To address this, a new UC Berkeley, University of Maryland and UC Irvine study sets out to identify the pitfalls that can cause instability in the GPT-3 language model and proposes a contextual calibration procedure that consistently improves GPT-3 (and GPT-2) accuracy across different prompt format choices and examples.
Typically, a natural language prompt is fed to neural autoregressive language models to ensure they perform few-shot learning using in-context learning. The prompt consists of three components: a format, a set of training examples, and a permutation of the training examples.
The researchers first studied how GPT-3’s accuracy changes across different prompts. They conducted sentiment analysis task experiments on three GPT-3 model sizes (2.7B, 13B, and 175B parameters) trained on SST-2 datasets, and observed high variance in GPT-3’s accuracy across the prompts’ training examples, permutation of examples, as well as format. Surprising, varying the permutation of the training examples could cause accuracy to range from 54.3 percent to near state-of-the-art (93.4 percent).
Accuracy across training sets, permutations and formats
The researchers next analyzed factors that contribute to GPT-3 instability, identifying three biases behind the accuracy variance:
Majority Label Bias GPT-3 is biased towards answers that are frequent in the prompt. The majority label bias helps explain why different choices for the training examples heavily influence GPT-3’s accuracy — as this shifts the distribution of model predictions.
Recency Bias The model’s majority label bias is aggravated by its recency bias: the tendency to repeat answers that appear towards the end of the prompt. Overall, recency bias helps to explain why the permutation of the training examples is important.
Common Token Bias GPT-3 is biased towards outputting tokens that are common in its pretraining distribution. The common token bias helps explain why the choice of label names is important, and why the model struggles with rare answers.
The team says these three biases together tend to contribute to a simple shift in a model’s output distribution.
Inspired by the idea that model biases towards certain answers can be estimated by feeding content-free inputs, the researchers proposed a novel data-free contextual calibration procedure to infer parameters. To evaluate the contextual calibration’s effectiveness, they conducted experiments on text classification, fact retrieval and information extraction tasks across different datasets (AGNews, MIT Director, DBPedia, TREC etc.).
Mean accuracy comparison across different training example choices for different datasets and model sizes. The steep red lines on all three model sizes indicate that few-shot learning can be highly unstable across different numbers of training examples. The more stable blue lines show that the calibration method improves the accuracy and robustness of GPT-3 models.Contextual calibration improves accuracy across a range of tasks
The proposed contextual calibration method improves the accuracy and reduces the variance of GPT-3 models, boosting average and worst-case absolute accuracy by up to 30 percent. The study highlights the need for better understanding and analysis of the dynamics of in-context learning.
The paper Calibrate Before Use: Improving Few-Shot Performance of Language Models is on arXiv.
Dreams take us to what feels like a different reality. They also happen while we’re fast asleep. So, you might not expect that a person in the midst of a vivid dream would be able to perceive questions and provide answers to them. But a new study reported in the journal Current Biology on February 18, 2021, shows that, in fact, they can.
“We found that individuals in REM sleep can interact with an experimenter and engage in real-time communication,” said senior author Ken Paller of Northwestern University. “We also showed that dreamers are capable of comprehending questions, engaging in working-memory operations, and producing answers.
“Most people might predict that this would not be possible — that people would either wake up when asked a question or fail to answer, and certainly not comprehend a question without misconstruing it.”
While dreams are a common experience, scientists still haven’t adequately explained them. Relying on a person’s recounting of dreams is also fraught with distortions and forgotten details. So, Paller and colleagues decided to attempt communication with people during lucid dreams.
This photo shows Konkoly watching brain signals from a sleeping participant in the lab. Researchers are working to expand and refine two-way communications with sleeping people so more complex conversations may one day be possible. Credit: K. Konkoly
“Our experimental goal is akin to finding a way to talk with an astronaut who is on another world, but in this case the world is entirely fabricated on the basis of memories stored in the brain,” the researchers write. They realized finding a means to communicate could open the door in future investigations to learn more about dreams, memory, and how memory storage depends on sleep, the researchers say.
The researchers studied 36 people who aimed to have a lucid dream, in which a person is aware they’re dreaming. The paper is unusual in that it includes four independently conducted experiments using different approaches to achieve a similar goal. In addition to the group at Northwestern University in the U.S., one group conducted studies at Sorbonne University in France, one at Osnabrück University in Germany, and one at Radboud University Medical Center in the Netherlands.
“We put the results together because we felt that the combination of results from four different labs using different approaches most convincingly attests to the reality of this phenomenon of two-way communication,” said Karen Konkoly, a PhD student at Northwestern University and first author of the paper. “In this way, we see that different means can be used to communicate.”
This photo shows Mazurek in a full EEG rig just before a sleep session in the lab. The electrodes on his face will detect the movement of his eyes as he sleeps. Credit: C. Mazurek
One of the individuals who readily succeeded with two-way communication had narcolepsy and frequent lucid dreams. Among the others, some had lots of experience in lucid dreaming and others did not. Overall, the researchers found that it was possible for people while dreaming to follow instructions, do simple math, answer yes-or-no questions, or tell the difference between different sensory stimuli. They could respond using eye movements or by contracting facial muscles. The researchers refer to it as “interactive dreaming.”
Konkoly says that future studies of dreaming could use these same methods to assess cognitive abilities during dreams versus wake. They also could help verify the accuracy of post-awakening dream reports. Outside of the laboratory, the methods could be used to help people in various ways, such as solving problems during sleep or offering nightmare sufferers novel ways to cope. Follow-up experiments run by members of the four research teams aim to learn more about connections between sleep and memory processing, and about how dreams may shed light on this memory processing.
Reference: “Real-time dialogue between experimenters and dreamers during REM sleep” by Karen R. Konkoly, Kristoffer Appel, Emma Chabani, Anastasia Mangiaruga, Jarrod Gott, Remington Mallett, Bruce Caughran, Sarah Witkowski, Nathan W. Whitmore, Christopher Y. Mazurek, Jonathan B. Berent, Frederik D. Weber, Basak Türker, Smaranda Leu-Semenescu, Jean-Baptiste Maranci, Gordon Pipa and Isabelle Arnulf, 18 February 2021, Current Biology. DOI: 10.1016/j.cub.2021.01.026
This work was supported by the Mind Science Foundation, National Science Foundation, Société Française de Recherche et Médecine du Sommeil (SFRMS), Hans-Mühlenhoff-Stiftung Osnabrück, a Vidi grant from the Netherlands Organisation for Scientific Research (NWO), and COST Action CA18106 supported by COST (European Cooperation in Science and Technology). Students in Paller’s lab group have also developed a smartphone app that aims to make it easier for people to achieve lucidity during their dreams: https://pallerlab.psych.northwestern.edu/dream
By UNIVERSITY OF MISSOURI-COLUMBIA FEBRUARY 24, 2021
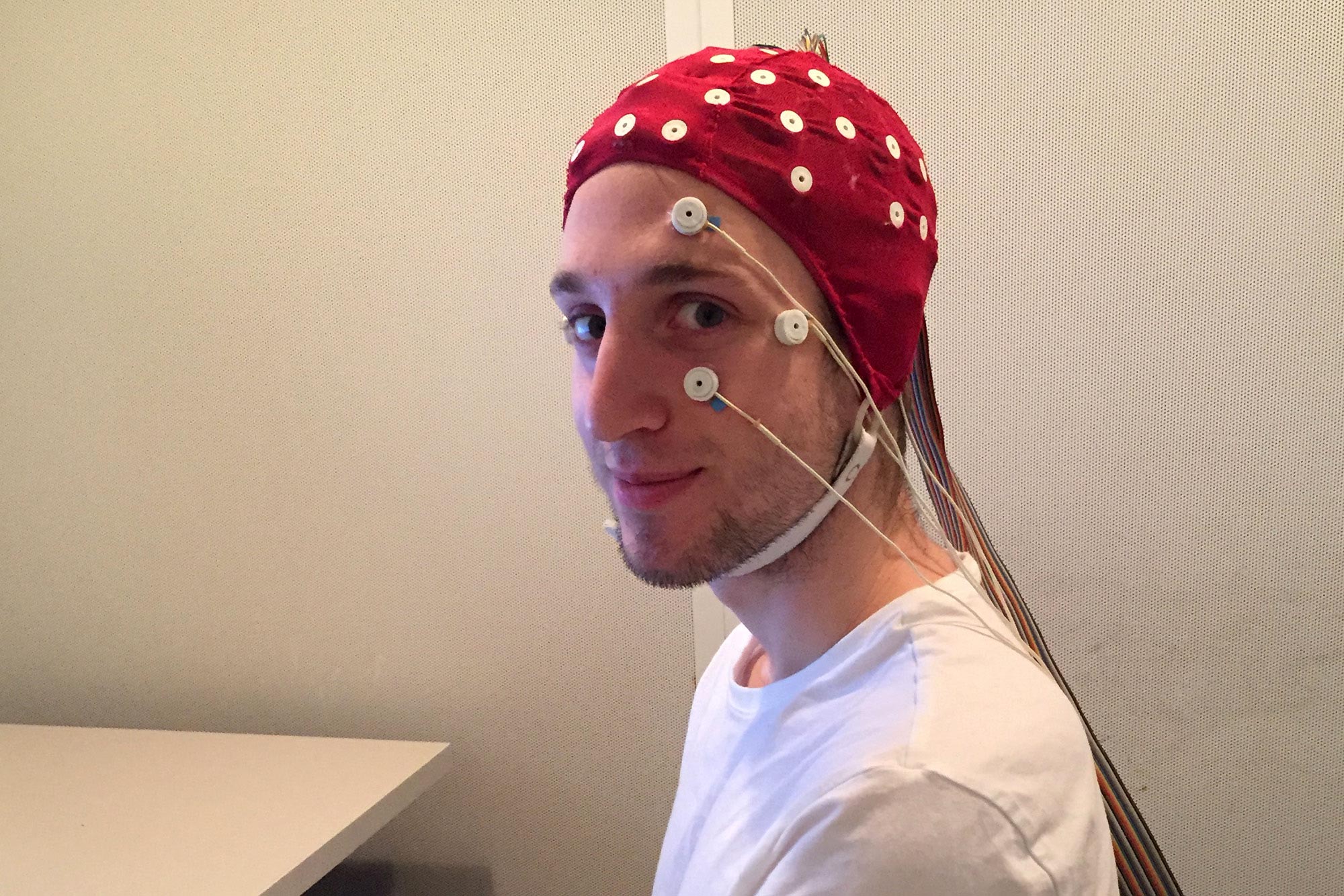
University of Missouri engineers are advancing the commercial market for wearable bioelectronics by developing a large-scale manufacturing plan for a customizable device capable of simultaneously tracking multiple vital signs such as blood pressure, heart activity and skin hydration. Credit: University of Missouri
A University of Missouri engineer received a grant from the National Science Foundation to plan for large-scale manufacturing of an on-skin, wearable bioelectronic device.
One day, a wearable, bioelectronic device could wirelessly transmit a person’s vital signs — potentially providing critical information for early detection of health issues such as COVID-19 or heart disease — to a healthcare provider, eliminating the need for an in-person visit while also saving lives.
The interest for wearable bioelectronics has grown in recent years, largely fueled by the growing demand for fitness trackers that can record workouts and monitor a person’s health — from heart rate to quality of sleep. Now, University of Missouri engineers are advancing the commercial market for wearable bioelectronics by developing a large-scale manufacturing plan for a customizable device capable of simultaneously tracking multiple vital signs such as blood pressure, heart activity and skin hydration.
Zheng Yan. Credit: University of Missouri
“While the biosensors for these devices have already been developed, we now want to combine them to mass produce a porous patch with multiple bioelectronic components,” said Zheng Yan, an assistant professor in the College of Engineering. “The components can also be customized to fit the individual health needs of the user.”
Yan recently received a more than $500,000 grant from the National Science Foundation’s Faculty Early Career Development Program, or CAREER, to begin a plan for mass production of the low-cost device.
The grant builds on some of Yan’s previous work demonstrating a proof of concept of a small patch that works as a breathable and waterproof on-skin electronic device with passive cooling capabilities. Now, he is working to increase production of that concept device for large-scale distribution.
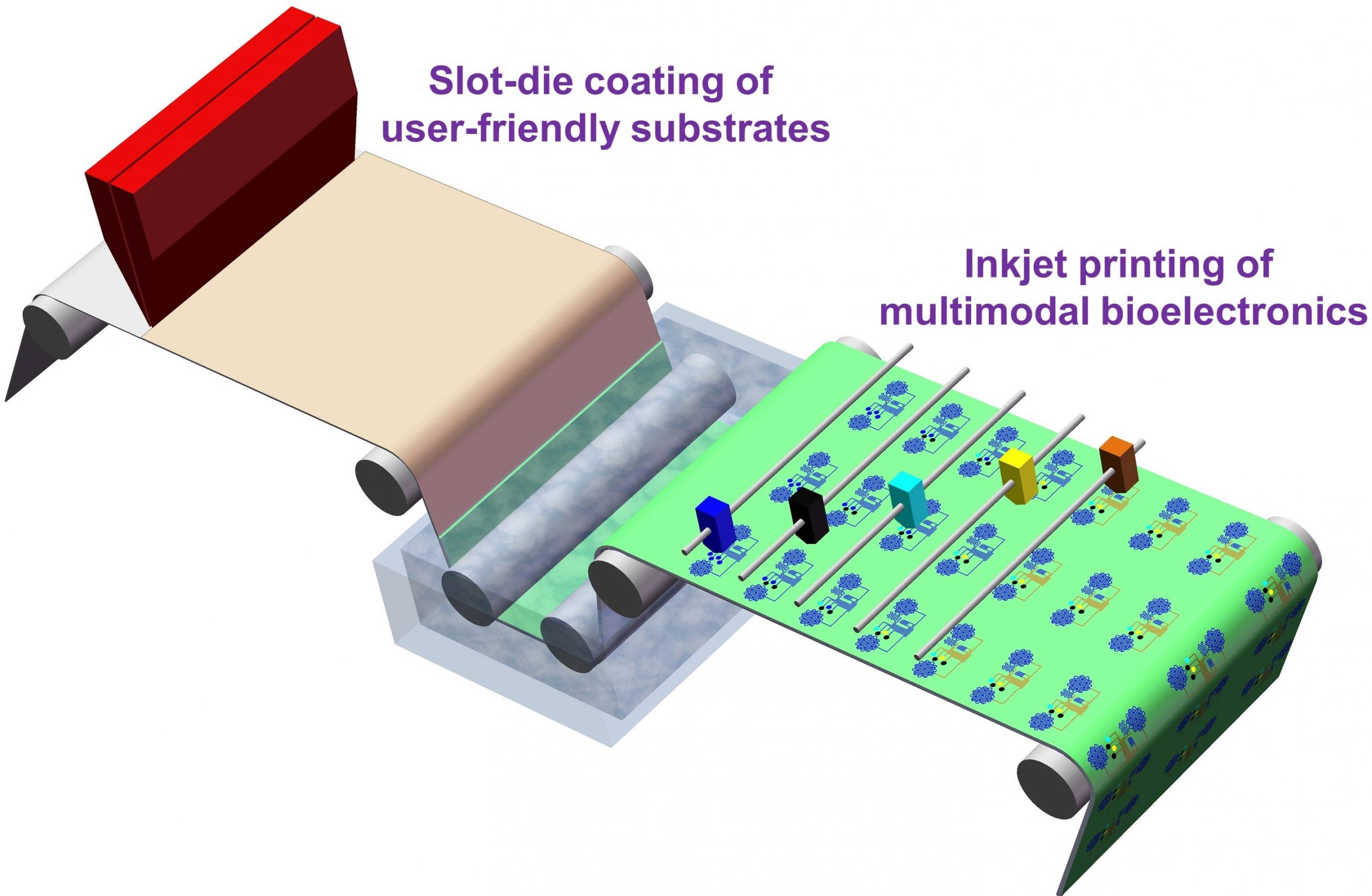
Yan said existing wearable devices usually consist of bioelectronics supported by a flexible, solid material — typically plastic or silicone — called a substrate. He wants to optimize the material to be soft, breathable, comfortable, lightweight and waterproof. Also, in order to mass produce the bioelectronic sensors, Yan is researching how to print them directly onto the supportive material using a method called mask-free inkjet printing.
“In the future, if we want to be able to widely implement the use of wearable biomedical devices, due to the size of production it should have a low manufacturing cost,” Yan said. “Therefore, using this grant we want to determine how to achieve continuous, scalable fabrication of such devices in an effort to keep our production costs as low as possible and transfer those cost savings to the consumer.”
The grant, “Solution based, continuous manufacturing or user friendly on skin electronics for customized health monitoring,” was awarded by the National Science Foundation (2045101).
At left, ions being lost from the confined plasma and following the magnetic field lines to the material diverter plates in the gyrokinetic simulation code XGC1. At right, an XGC1 simulation of edge turbulence in DIII-D plasma, showing the plasma turbulence changing the eddy structure to isolated blobs (represented by red color) in the vicinity of the magnetic separatrix (black line). Credit: Kwan-Liu Ma’s research group, University of California Davis; David Pugmire and Adam Malin, ORNL
Nuclear fusion, the same kind of energy that fuels stars, could one day power our world with abundant, safe, and carbon-free energy. Aided by supercomputers Summit at the US Department of Energy’s (DOE’s) Oak Ridge National Laboratory (ORNL) and Theta at DOE’s Argonne National Laboratory (ANL), a team of scientists strives toward making fusion energy a reality.
Fusion reactions involve two or more atomic nuclei combining to form different nuclei and particles, converting some of the atomic mass into energy in the process. Scientists are working toward building a nuclear fusion reactor that could efficiently produce heat that would then be used to generate electricity. However, confining plasma reactions that occur at temperatures hotter than the sun is very difficult, and the engineers who design these massive machines can’t afford mistakes.
To ensure the success of future fusion devices—such as ITER, which is being built in southern France—scientists can take data from experiments performed on smaller fusion devices and combine them with massive computer simulations to understand the requirements of new machines. ITER will be the world’s largest tokamak, or device that uses magnetic fields to confine plasma particles in the shape of a donut inside, and will produce 500 megawatts (MW) of fusion power from only 50 MW of input heating power.
One of the most important requirements for fusion reactors is the tokamak’s divertor, a material structure engineered to remove exhaust heat from the reactor’s vacuum vessel. The heat-load width of the divertor is the width along the reactor’s inner walls that will sustain repeated hot exhaust particles coming in contact with it.
A team led by C.S. Chang at Princeton Plasma Physics Laboratory (PPPL) has used the Oak Ridge Leadership Computing Facility’s (OLCF’s) 200-petaflop Summit and Argonne Leadership Computing Facility’s (ALCF’s) 11.7-petaflop Theta supercomputers, together with a supervised machine learning program called Eureqa, to find a new extrapolation formula from existing tokamak data to future ITER based on simulations from their XGC computational code for modeling tokamak plasmas. The team then completed new simulations that confirm their previous ones, which showed that at full power, ITER’s divertor heat-load width would be more than six times wider than was expected in the current trend of tokamaks. The results were published in Physics of Plasmas.
Using Eureqa, the team found hidden parameters that provided a new formula that not only fits the drastic increase predicted for ITER’s heat-load width at full power but also produced the same results as previous experimental and simulation data for existing tokamaks. Among the devices newly included in the study were the Alcator C-Mod, a tokamak at the Massachusetts Institute of Technology (MIT) that holds the record for plasma pressure in a magnetically confined fusion device, and the world’s largest existing tokamak, the JET (Joint European Torus) in the United Kingdom.
“If this formula is validated experimentally, this will be huge for the fusion community and for ensuring that ITER’s divertor can accommodate the heat exhaust from the plasma without too much complication,” Chang said.
ITER deviates from the trend
The Chang team’s work studying ITER’s divertor plates began in 2017 when the group reproduced experimental divertor heat-load width results from three US fusion devices on the OLCF’s former Titan supercomputer: General Atomics’ DIII-D toroidal magnetic fusion device, which has an aspect ratio similar to ITER; MIT’s Alcator C-Mod; and the National Spherical Torus Experiment, a compact low-aspect-ratio spherical tokamak at PPPL. The presence of steady “blobby”-shaped turbulence at the edge of the plasma in these tokamaks did not play a significant role in widening the divertor heat-load width.
The researchers then set out to prove that their XGC code, which simulates particle movements and electromagnetic fields in plasma, could predict the heat-load width on the full-power ITER’s divertor surface. The presence of dynamic edge turbulence—different from the steady blobby-shaped turbulence present in the current tokamak edge—could significantly widen the distribution of the exhaust heat, they realized. If ITER were to follow the current trend of heat-load widths in present-day fusion devices, its heat-load width would be less than a few centimeters—a dangerously narrow width, even for divertor plates made of tungsten, which boasts the highest melting point of all pure metals.
The team’s simulations on Titan in 2017 revealed an unusual jump in the trend—the full-power ITER showed a heat-load width more than six times wider than what the existing tokamaks implied. But the extraordinary finding required more investigation. How could the full-power ITER’s heat-load width deviate so significantly from existing tokamaks?
Scientists operating the C-Mod tokamak at MIT cranked the device’s magnetic field up to ITER value for the strength of the poloidal magnetic field, which runs top to bottom to confine the donut-shaped plasma inside the reaction chamber. The other field used in tokamak reactors, the toroidal magnetic field, runs around the circumference of the donut. Combined, these two magnetic fields confine the plasma, as if winding a tight string around a donut, creating looping motions of ions along the combined magnetic field lines called gyromotions that researchers believe might smooth out turbulence in the plasma.
Scientists at MIT then provided Chang with experimental data from the Alcator C-Mod against which his team could compare results from simulations by using XGC. With an allocation of time under the INCITE (Innovative and Novel Computational Impact on Theory and Experiment) program, the team performed extreme-scale simulations on Summit by employing the new Alcator C-Mod data using a finer grid and including a greater number of particles.
The interior of MIT’s Alcator C-Mod tokamak. Credit: Robert Mumgaard, MIT
“They gave us their data, and our code still agreed with the experiment, showing a much narrower divertor heat-load width than the full-power ITER,” Chang said. “What that meant was that either our code produced a wrong result in the earlier full-power ITER simulation on Titan or there was a hidden parameter that we needed to account for in the prediction formula.”
Machine learning reveals a new formula
Chang suspected that the hidden parameter might be the radius of the gyromotions, called the gyroradius, divided by the size of the machine. Chang then fed the new results to a machine learning program called Eureqa, presently owned by DataRobot, asking it to find the hidden parameter and a new formula for the ITER prediction. The program spit out several new formulas, verifying the gyroradius divided by the machine size as being the hidden parameter. The simplest of these formulas most agreed with the physics insights.
Chang presented the findings at various international conferences last year. He was then given three more simulation cases from ITER headquarters to test the new formula. The simplest formula successfully passed the test. PPPL research staff physicists Seung-Hoe Ku and Robert Hager employed the Summit and the Theta supercomputers for these three critically important ITER test simulations. Summit is located at the OLCF, a DOE Office of Science User Facility at ORNL. Theta is located at ALCF, another DOE Office of Science User Facility, located at ANL.
In an exciting finding, the new formula predicted the same results as the present experimental data—a huge jump in the full-power ITER’s heat-load width, with the medium-power ITER landing in between.
“Verifying whether ITER operation is going to be difficult due to an excessively narrow divertor heat-load width was something the entire fusion community has been concerned about, and we now have hope that ITER might be much easier to operate,” Chang said. “If this formula is correct, design engineers would be able to use it in their design for more economical fusion reactors.”
A big data problem
Each of the team’s ITER simulations consisted of 2 trillion particles and more than 1,000 time steps, requiring most of the Summit machine and one full day or longer to complete. The data generated by one simulation, Chang said, could total a whopping 200 petabytes, eating up nearly all of Summit’s file system storage.
“Summit’s file system only holds 250 petabytes’ worth of data for all the users,” Chang said. “There is no way to get all this data out to the file system, and we usually have to write out some parts of the physics data every 10 or more time steps.”
This has proven challenging for the team, who often found new science in the data that was not saved in the first simulation.
“I would often tell Dr. Ku, “I wish to see this data because it looks like we could find something interesting there,” only to discover that he could not save it,” Chang said. “We need reliable, large-compression-ratio data reduction technologies, so that’s something we are working on and are hopeful to be able to take advantage of in the future.”
Chang added that staff members at both the OLCF and ALCF were critical to the team’s ability to run codes on the centers’ massive high-performance computing systems.
“Help rendered by the OLCF and ALCF computer center staff—especially from the liaisons—has been essential in enabling these extreme-scale simulations,” Chang said.
The team is anxiously awaiting the arrival of two of DOE’s upcoming exascale supercomputers, the OLCF’s Frontier and ALCF’s Aurora, machines that will be capable of a billion billion calculations per second, or 1018 calculations per second. The team will next include more complex physics, such as electromagnetic turbulence in a more refined grid with a greater number of particles, to verify the new formula’s fidelity further and improve its accuracy. The team also plans to collaborate with experimentalists to design experiments to further validate the electromagnetic turbulence results that will be obtained on Summit or Frontier.
“Constructing a New Predictive Scaling Formula for ITER’s Divertor Heat-Load Width Informed by a Simulation-Anchored Machine Learning” is published in Physics of Plasmas.
More information: C. S. Chang et al. Constructing a new predictive scaling formula for ITER’s divertor heat-load width informed by a simulation-anchored machine learning, Physics of Plasmas (2021). DOI: 10.1063/5.0027637Journal information:Physics of PlasmasProvided by Oak Ridge National Laboratory
Monday’s videos of the successful Mars landing of Perseverance in the Jezero Crater was just the opening act for what NASA’s fastest and best-equipped rover will do for scientific research on the Red Planet.
Act two will be a new type of helicopter—also known as an eVTOL (Electric Vertical Take-Off and Landing) aircraft. Weighing just four pounds, Ingenuity hitched a nearly 300-million-mile ride to Mars, attached to the underbelly of Perseverance. Nicknamed “Ginny,” the VTOL is powered by six lithium-ion batteries that account for just 15 percent of its weight and are rechargeable from the solar array on top of the airframe.https://162ab2d637d24a08852c1156d3f67ae1.safeframe.googlesyndication.com/safeframe/1-0-37/html/container.html
“Classified as a technology demonstration, Ingenuity will conduct five flights, beginning sometime in April,” Steven Agid, an aerospace engineer at the Kennedy Space Center, told Robb Report. “Starting with simple vertical lift operations, each flight will last up to 90 seconds, ranging from 10 to 15 feet above Mars’s surface. Subsequent tests will expand Ingenuity’s flight envelope, with the longest flight covering three football fields.”
Ingenuity—nicknamed “Ginny”—traveled 300 million miles attached to the underbelly of Perseverance. Now it will conduct its own test flights over the Red Planet’s surface. Courtesy NASA
Ingenuity is only 19.2 inches tall, with four carbon-fiber blades arranged into two, 4-foot-long counter-rotating rotors that spin at roughly 2,400 RPM—or about five times faster than a typical helicopter—due to Mars’s ultrathin atmosphere. With about five inches of clearance off the ground, Ingenuity will carry two cameras: one color with a horizon-facing view for terrain images and one black-and-white for navigation.
Although Ingenuity can communicate with NASA through Perseverance, the flight tests will not be remotely controlled by Cape Canaveral. It takes almost 12 minutes for a signal from Earth to reach Mars and the same for a response. With such a delay, the eVTOL was preprogrammed with test scripts to be performed when it receives activation signals.
To mitigate all the imaginable risks associated with a first flight in an unpredictable and uncontrollable environment, the Jet Propulsion Laboratory (JPL) carried out an extensive simulation campaign at its CalTech research center in Pasadena, California. From wind-tunnel tests to conditions recreating Mars’s extreme temperatures and much lower gravity, Ingenuity sustained all known conditions it will likely encounter on the Red Planet.https://162ab2d637d24a08852c1156d3f67ae1.safeframe.googlesyndication.com/safeframe/1-0-37/html/container.html
The space eVTOL was designed to fly in Mars’s ultra-thin atmosphere, with gravity that is 62 percent lower than Earth’s. Courtesy NASA
While ideal conditions for another Mars mission are 26 months away, Ingenuity’s validation of its flight characteristics and capabilities on the Red Planet will give NASA and JPL plenty of time to design, build, and test the next eVTOL to fly on Mars. Subsequent missions will be for freight and eventually the electric aircraft will be used for human transport.
Muscat: A study at Sultan Qaboos University reveals that those who do not sleep well are at risk of tumours.
New research by Dr Elias Said from the College of Medicine and Health Sciences at Sultan Qaboos University examines the effect of sleep deprivation on changes in immune cell functions, as well as on levels and the ability to proliferate in helper lymphocytes and its correlation with the level of chemically attractive proteins (chemokines).
These elements have great importance in the formation of effective immune responses. ADVERTISING
Dr Elias said, “The elements of the immune system of healthy volunteers were monitored for three weeks, as the participants slept normally (for more than seven hours per day) in the first and third weeks and underwent chronic partial sleep deprivation (sleeping for only four hours a day, similar to the lack of sleep that people who sleep for less than seven hours every day suffer from).”
The results of the research showed that the ability of the volunteers’ immune system to swallow and kill bacteria had been reduced due to insufficient sleep. As the ability of neutrophil immune cells, which are essential cells in fighting bacterial infection, to swallow these germs, and to activate enzymes inside them that lead to killing germs, had decreased. The results also indicated a change in the balance of some elements of the immune system, as the amount of the protein chemically attracting cells (chemocaine)
“CXCL 9” increased when sleeping for a few hours, which led to a lack of its balance with other chemokines that are “CXCL 10” as well as “CCL5”.
He added, “The results of the research also showed that the level of helper lymphocytes (T), which are the cells responsible for stimulating most cells of the immune system when contracting diseases, decreased due to lack of sleep, and this decrease was not due to a change in the proliferation of these cells as indicated by the levels of the nuclear protein. “KA67”, but that was related to the change in the balance between the “CXCL 9” and “CXCL 10” chemicals, which occurred as a result of reduced sleep hours. Confirming that these results suggest that people who do not sleep enough daily become more susceptible to infection with germs, and they may have an increased risk of developing tumors.”
Dr Elias, stressed on the importance of sleeping enough every day in order for the immune system to function properly, saying that those who do not sleep enough must undergo periodic checks for the possibility of infection with diseases.
The research results were published in the “Sleep and Breathing” magazine, which is the official journal of the European, Australian, Japanese and Korean Academies of Sleep and Dental Medicine.
The Dodow is a consumer device that aims to help users sleep, through biofeedback. The idea is to synchronise one’s breathing with the gentle rhythm of the device’s blue LEDs, which helps slow the heartrate and enables the user to more easily drift off to sleep. Noting that the device is essentially a breathing LED and little more, [Daniel Shiffman] set about building his own from scratch.
An ATTiny85 runs the show; no high-powered microcontrollers are necessary here. It’s hooked up to three 5mm blue LEDs, which are slowly ramped up and down to create a smooth, attractive breathing animation. The LEDs are directed upward so that their glow can be seen on the ceiling, allowing the user to lay on their back when getting ready for sleep. It’s all wrapped up in a 3D printed enclosure that is easily modifiable to suit a variety of battery solutions; [Daniel] chose the DL123A for its convenient voltage and battery life in this case. The design is available on Thingiverse for those looking to spin their own.
Humans’ desire to set foot on another planet – even make it their home is not distant as visionaries like Elon Musk are headstrong about their goal of colonizing Mars in the next few decades. More than a pipedream, the foundation has been laid by NASA’s unmanned missions to the red planet – the freshest one being the landing of the Mars Perseverance rover. While rovers scout the planet’s surface for signs of water and other intricate details for future missions, here on planet earth, imaginative designers are letting loose their creative bits to show us what the future could be like.
This bug-like rover that looks like the big daddy of the compact Mars rovers that we have seen over the years is, in fact, a waste disposal vehicle for the harsh terrain of the red planet. Called the D25 Modular Rover, the design comes to the courtesy of Joshua Kotter, who has reimagined the shape and function of a vehicle to make it look like its tailormade for the jarred landscape and severe weather conditions of Mars. The three-part vehicle is made of the modular platform chassis that’s electrically driven, has a cabin crew module, and the main waste disposal module. While the first and second are a given surety on the vehicle, the waste disposal module can be swapped with other customizable modules depending on the need.
Joshua gives the modular rover a very upbeat character that’s bold with the NASA, Tesla, and SpaceX branding. The Cybertruck-like sharp aesthetic is apparent in the rover as it is made to scale abrasive terrain commonly found on the planet. The module could also be readied for any reconnaissance missions should an alien species decide to have the first rights on the planet. Who knows what the uncertain future holds for humanity as we are bound to encounter other life forms in the galaxy and our universe eventually. The D25 Modular Rover looks prepared for that eventuality!








 in the vicinity of the magnetic separatrix (black line). Credit: Kwan-Liu Ma’s research group, University of California Davis; David Pugmire and Adam Malin, ORNL")

 Courtesy NASA
Courtesy NASA










{kind=link}
{kind=link}
{kind=link}
{kind=link}